






星标“医工学人”,第一时间获取医工交叉领域新闻动态~
训练一个能理解你意图的智能外骨骼,通常需要价值数百万美元的实验室设备和数千小时的专家标注。一项新技术通过引入“模拟传感器”作为通用翻译层,成功利用免费的公共数据集和未经标注的原始数据,训练出了性能好且便宜的AI控制器。这不仅将数据需求削减了95%,更可能彻底改变康复机器人的研发和商业化路径。
想象一下,你要为一款新型智能假肢或外骨骼开发“大脑”。传统的做法不是写代码,而是开启一场漫长而昂贵的过程。
首先,你需要邀请数十位受试者,让他们穿着你的原型机,在布满红外运动捕捉镜头和测力跑道的实验室内,一遍遍行走、奔跑、跳跃。这些设备每秒钟产生海量数据,但真正的难题在于“标注”——你需要将外骨骼传感器读到的每一帧数据,与人体真实的生物关节力矩(即肌肉和骨骼产生的真实力量)精确对应起来。这个过程需要生物力学专家耗费数百小时的人工校对。
文献作者直言不讳地指出了这个痛点:“研究人员必须从其外骨骼传感器和地面真值源(通常是光学运动捕捉系统和测力台)记录时间同步数据。”这套配置不仅昂贵且稀缺,更棘手的是,数据是“设备特异性”的——你每修改一次传感器的位置、更换一版原型机,或者改变控制策略,整个痛苦的数据收集过程就必须重来一遍。
其结果就是,数据驱动的外骨骼控制技术虽然潜力巨大,但其研发被牢牢锁死在少数顶尖实验室的“玻璃房”内,难以规模化,更遑论走向消费市场。
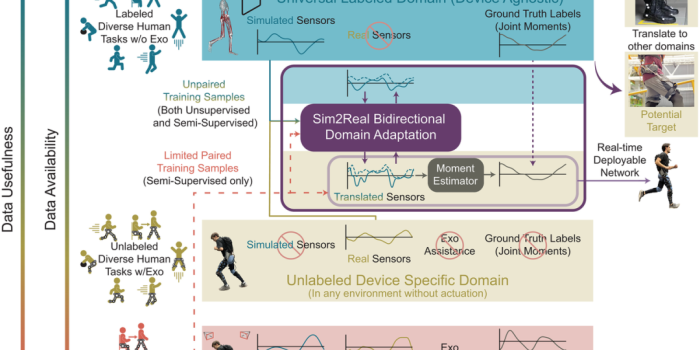
佐治亚理工学院的研究团队提出的解决方案,不是去降低数据采集的成本,而是巧妙地“绕过”了它。他们的核心思想是:创造一个通用的、虚拟的“中间人”,来连接免费的公开数据和昂贵的设备数据。
图1. 作者的策略:用成本更低的数据替代昂贵的设备特异性数据。方法:采用带有模拟传感器的生物力学建模域作为聚合数据的通用域。为了使用这些数据,出了一个网络,该网络基于来自特定设备的无标签数据,执行双向域自适应,将模拟传感器翻译到任何特定设备域。这些翻译后的数据可用于训练下游深度学习模型(在文章的案例中是力矩估计器),这些模型可实时部署在设备上。此策略可用于为新设备和新关节创建模型。完全无标签的框架(无监督)是可行的,但可选的带标签设备特异性数据可能有用(半监督)。
这个中间人,就是基于生物力学模型(如OpenSim)的“模拟传感器域”。
工作原理拆解:
1)源域(免费且丰富):
研究者从一个名为D_hs的公共数据集入手,里面包含了12名受试者进行28种动作的生物力学数据。这些数据有完整的力矩标签,但没有外骨骼。通过算法,他们可以为这些数据“虚拟”安装上任何类型、任何位置的传感器(如IMU和编码器)。
2)目标域(少量且未标注):
他们让10名受试者穿着目标外骨骼(但不开机),随意做动作,只记录下外骨骼自身传感器(IMU和编码器)的原始数据,这些数据没有昂贵的力矩标签。
3)核心黑科技——双向域自适应网络(CycleGAN+U-Net):
团队训练了一个深度学习网络,其任务是学习在上述虚拟传感器数据和真实外骨骼传感器数据之间进行“翻译”。网络包含两个生成器,一个负责将虚拟数据“翻译”成看起来像真实数据的信号(T_s→t),另一个则反之(T_t→s)。通过对抗训练和循环一致性损失(Cycle-Consistency Loss),网络学会了捕捉真实世界的传感器噪声、人体与设备交互的动态特征等复杂信息。
图2. 有限任务和受试者训练集上的任务优化与性能表现。在通过提供跨所有任务最低RMSE的任务对任务优化进行初始化后,通过最大化对其他任务的泛化分数来顺序添加任务(A)。(B)显示了未选中任务和选中任务相应的RMSE。当我们的方法与最佳情况模型在统计上无显著差异时,在九个任务后终止优化。使用此优化后的任务列表,我们比较了我们的方法在髋部(C)和膝部(D)的性能,与一个单独优化的、无域自适应的基线模型(但使用相同有限数量的任务)进行对比。通过基于四个优化后的任务对受试者进行交叉折叠,我们评估了在训练中顺序增加带标签受试者数量时,我们的方法及基线方法在髋部(E)和膝部(F)的平均RMSE。我们的方法和基线方法与一个使用来自所有任务和受试者的带标签数据训练的最佳情况模型进行比较。误差线代表五个交叉折叠、留出受试者的标准差(为清晰起见,在(A)和(B)中省略)。统计学显著性通过控制所有九个任务((C)和(D))以及所有13名受试者((E)和(F))中的错误发现率(q<0.05)来确定。
新旧技术路径对比:
最终,这个训练好的T_s→t翻译器,可以将海量的、免费的、带标签的公共数据,实时转换成目标外骨骼能“听懂”的传感器信号,并以此训练出一个高精度的关节力矩估计模型,用于实时控制。
这项研究的验证环节非常扎实,不仅验证了精度,更验证了其对人体代谢的实际收益。
1.离线数据验证:在未参与训练的8名新受试者身上,论文提出的半监督方法(使用4人×4任务的少量标签数据)在髋、膝关节力矩估计的均方根误差(RMSE)上,相比于需要全部数据的最佳模型,仅增加了11-20%。而无监督方法(不使用任何目标域标签)的误差增加为20-44%。相比之下,不使用域自适应的基线模型,其误差增加高达36-60%。这表明,新方法用5%的数据,达到了接近100%数据训练的精度。
图3. 使用翻译后数据训练的力矩估计器的离线模型性能。对于半监督情况,我们的方法与基线方法的性能以与最佳情况模型相比的RMSE增加百分比的形式呈现,分别针对髋部(A)和膝部(B)。对于无监督情况,在髋部(C)和膝部(D)也呈现了类似的结果。首先对所有28种活动取平均值,然后对受试者取平均值。误差线代表八名受试者的标准差,星号表示由配对t检验确定的统计学显著性。半监督情况(E)和无监督情况(F)下,针对28项任务中的每一项,地面真实关节力矩与估计值之间的R²值在髋部和膝部呈现。每个点代表八名受试者的平均值,但为视觉清晰省略了误差线;每个三角形代表所有任务的平均值。
2. 实时控制验证:团队将训练好的模型部署到一台真实的髋/膝外骨骼上,让8位新受试者执行多种任务。结果显示,半监督模型的实时估计精度与离线结果高度一致,髋关节R²达到0.71,膝关节R²达到0.75。
图4. 基于翻译数据训练的力矩估计器的实时模型性能。自主髋/膝外骨骼(A)将来自髋部和膝部编码器以及大腿和小腿IMU的测量值通过微处理器发送到板载机器学习协处理器进行实时推理。推理结果转换为执行器指令,提供双侧髋部和膝部辅助。(B)带有标签外骨骼数据(半监督)的模型包括四个任务。对于无监督和半监督模型,有七个实时任务是全新的;水平地面行走在半监督训练集中。无标签外骨骼数据和生物力学数据集包括所有任务。我们部署的模型与其基线模型的性能,在半监督情况下于髋部(C)和膝部(D),以及在无监督情况下于髋部(E)和膝部(F),以与最佳情况模型(事后计算)相比的RMSE增加百分比呈现。由于实时控制器不稳定,无监督基线模型是事后离线运行的。平均值先对所有八个测试任务取平均,然后对八名受试者取平均,误差线代表受试者间的标准差。星号表示由配对t检验确定的统计学显著性。半监督模型(G)、最佳情况模型(H)和无监督模型(I)的数据图示也已呈现。
3. 人体代谢收益验证——最关键的“金标准”:外骨骼好不好,最终看它能否帮人省力。在负重上举和5度斜坡行走两项高能耗任务中:
图5. 基于翻译数据训练的力矩估计器的净代谢成本比较。八名受试者在无外骨骼以及使用我们的两种控制器和最佳情况模型的情况下,执行了负重上举任务(A)和斜坡行走任务(B)。条形图表示每公斤体重的平均净代谢成本,误差线代表八名受试者的标准差。星号表示经Bonferroni校正的事后多重比较检验(P<0.05)确定的统计学显著性。代谢成本结果下方是每个部署控制器的髋部和膝部力矩的周期平均估计值。实时估计值按周期分割,然后分别按受试者平均。阴影区域代表八名受试者的标准差,实线代表平均值。
-
半监督模型使受试者的净代谢消耗分别降低了12.5%和14.6%,这与使用全部数据训练出的“最佳模型”(降低14.4%和13.6%)效果几乎无差。
-
无监督模型也分别实现了9.5%和13.8% 的降低,尽管在统计上略逊于前者,但已具备显著的生理学意义。
“我们的半监督模型……仅增加了11-20%的误差……我们的框架使研究人员能够在有限或无法获取标记的、设备特定数据的情况下,训练可实时部署的深度学习、任务无关型模型。”
这项研究的突破性,超越了外骨骼控制本身。
-
对行业研发模式的影响: 它颠覆了“硬件迭代必伴随昂贵的软件数据重采”的铁律。创业公司可以快速调整硬件设计,而无需为每次改动都重启整个数据采集流程。这将大大加速外骨骼从原型到产品的迭代周期。
-
打开个性化康复的大门: 该框架为训练针对特定人群(如脑卒中患者、渐冻症患者)的模型提供了新思路。为这些特殊人群收集大规模带标签数据集几乎不可能,但收集他们自由活动时的原始设备数据,并结合公共的、健康人群的生物力学数据进行域自适应,成为一条可行的技术路径。
-
解锁更复杂的AI算法: 通过此框架,研究者可以汇集来自多个开源数据库的力量,形成一个“虚拟大模型”训练集。这为未来在低功耗嵌入式设备上运行更庞大、更智能的强化学习或Transformer模型铺平了道路。
这项研究为可穿戴机器人的数据困境提供了一个精妙的解法,但它并非一个放之四海而皆准的“万能钥匙”。
正如研究者们自己所承认的,该框架目前验证的“任务边界”是28种预设的动作。对于完全没在训练集中出现过的、“零样本”(Zero-shot)的全新任务——比如一项未包含在内的新型体育运动或一种康复动作——其模型泛化能力尚未得到验证。从“预设任务”到“无限任务”,这之间需要跨越的鸿沟,可能不仅需要算法层面的优化,更需要对域自适应理论的底层逻辑进行重构。
另一个值得追问的问题是:当前的传感器翻译框架仅局限于IMU和编码器等运动学传感器。而像肌电信号(EMG)这类能更直接反映神经驱动和肌肉激活状态的生理信号,尚未被纳入这个翻译体系。毕竟,人体运动的终极指令来源于神经。如何构建一个能融合“物理运动”与“神经意图”的多模态翻译网络,或许是实现下一代直觉式人机交互的关键。
此外,关于“黑箱”的可解释性也留下了开放的课题:域自适应网络从大量无标注数据中究竟学到了什么?是对真实世界传感器噪声的鲁棒性,还是对人体穿戴设备后的自适应运动模式?初步分析(附图S9)表明两者兼有,但只有更深入、更清晰的解构,才能帮助我们设计出更高效、更稳健、不会在关键时刻“失语”的智能算法。
尽管如此,这项研究的贡献仍然是开创性的:它首次系统性地证明了,通过创建一个“模拟传感器”作为通用翻译层,可以将“昂贵、设备特异性数据”这一长期被接受为宿命的研发瓶颈,转变为一种可工程化、可规模化解决的范式问题。对于任何一个曾因数据集不足而被迫放弃复杂算法,或是在深夜的实验室里对着捉襟见肘的预算叹息的研发者来说,这本身就意味着一场值得关注的胜利。
Keaton L. Scherpereel et al. ,Deep domain adaptation eliminates costly data required for task-agnostic wearable robotic control.Sci. Robot.10,eads8652(2025).DOI:10.1126/scirobotics.ads8652
END
撰文 | 郝娅婷
编辑 | 吴苡齐
审核 | 医工学人理事会
扫码加入医工学人,进入综合及细分领域群聊,
参与线上线下交流活动
