






星标“医工学人”,第一时间获取医工交叉领域新闻动态~

眼科手术对精度要求极高,手术过程通常在显微镜下完成,产生大量富含时空动态信息的视频数据。虽然手术显微镜视频记录了海量的动态操作信息,但现有人工智能模型在临床应用中面临三大痛点:一是高质量标注的手术视频数据极度匮乏;二是大参数量模型难以满足术中实时推理的需求;三是 AI 模型与实际手术流程及医生操作缺乏深度融合。
近期,来自上海交通大学医学院附属新华医院、汕头大学·香港中文大学联合汕头国际眼科中心等团队在《Nature Biomedical Engineering》发表了题为《An ophthalmic video foundation model for surgical recognition and navigation with wet-lab porcine eye validation》的研究,提出了全球首个面向眼科手术的视频基础模型——OVFM(Ophthalmic Video Foundation Model)。该模型通过自监督学习从大规模手术视频中学习时空特征,并通过知识蒸馏实现轻量化部署,首次将基础模型真正集成到手术显微镜中,在猪眼白内障手术中验证了其提升手术表现、缩小医生经验差距的临床价值。
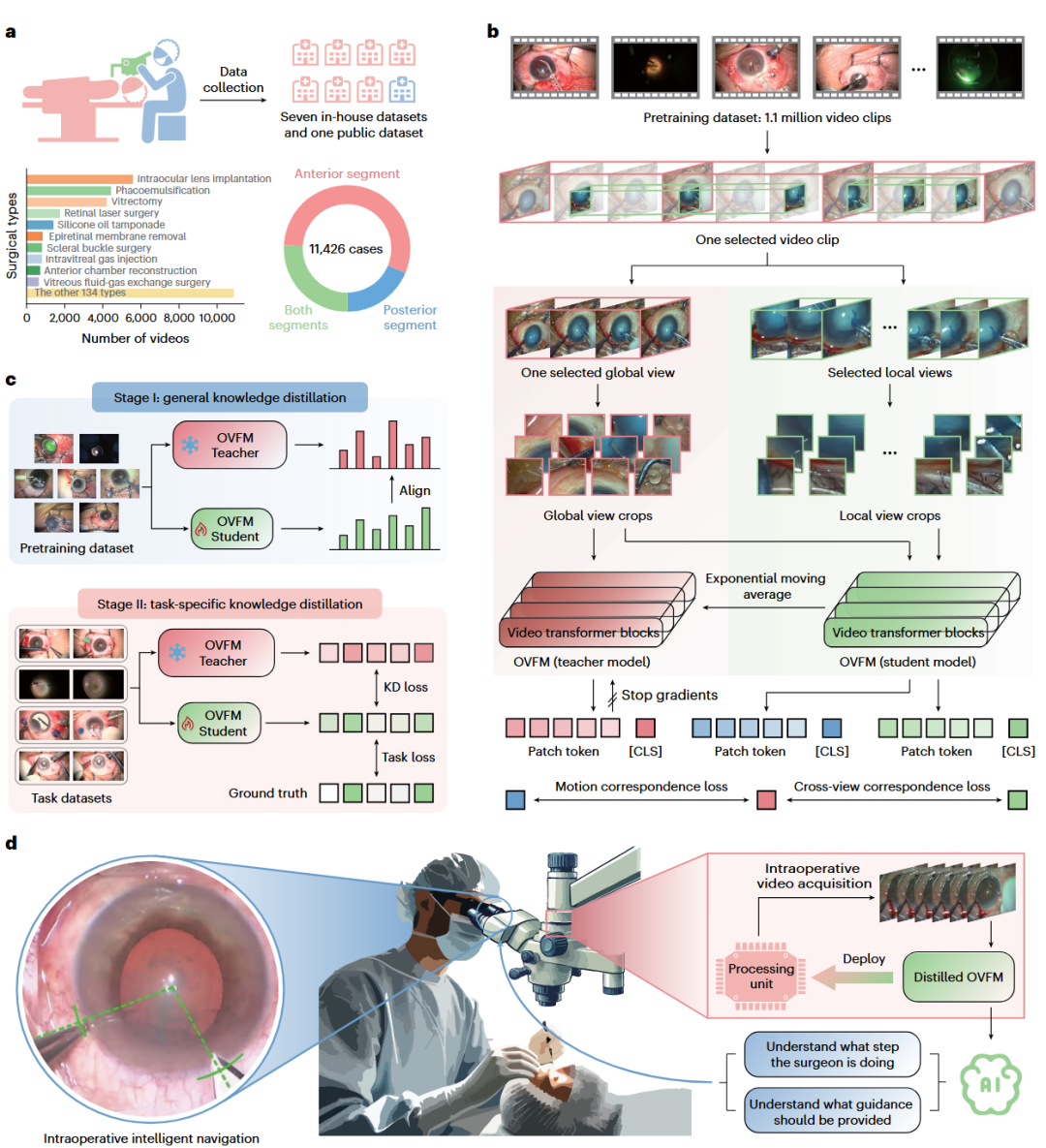
图 1 | 本研究概览。
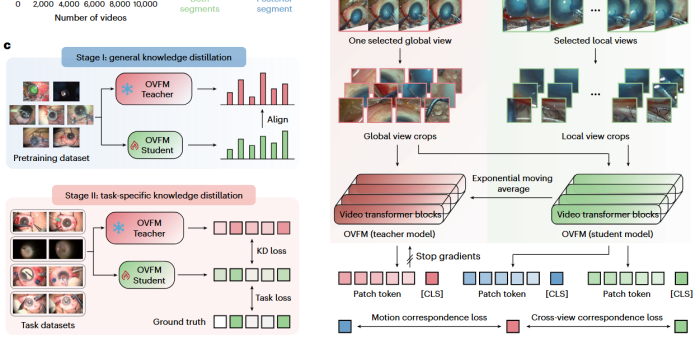
a,大规模眼科手术视频数据集的构建。b,利用包含 110 万个视频片段的下采样数据集对 OVFM 进行预训练的过程。c,两阶段知识蒸馏策略。d,将蒸馏后的 OVFM 集成到手术显微镜中。该模型部署于显微镜的处理单元内,通过理解手术场景并提供相关的导航信息,实现术中实时的步进式引导(step-specific guidance)。
眼科手术视频具有高度的动态性。为了让模型“看懂”手术,研究团队设计了一个基于自监督视频Transformer的预训练框架,旨在从海量无标注手术视频中学习通用的时空特征,并支持手术步骤识别、结构分割、实时导航等多种下游任务。 研究团队建立了目前规模最大的眼科手术视频数据集,涵盖来自8个医疗中心的11,426部显微手术视频,总时长超过7569小时,包含144种眼科手术类型(如前段白内障手术、后段玻璃体切除术等)。通过对视频进行稀疏采样,最终获得110万个视频片段,用于模型自监督预训练。 OVFM基于SVT(Self-supervised Video Transformer)架构,利用自监督学习策略,从海量未标注视频中提取手术器械与组织交互的时空特征。这使得模型不仅能识别“这是什么”,还能理解“正在发生什么动作”。 为了让庞大的基础模型能在普通显微镜处理单元上跑起来,研究团队设计了通用—特定的蒸馏方案。首先将教师模型的通用知识转移给轻量化的学生模型(SVT-tiny),再针对特定手术任务进行微调。最终,模型在参数量减少 15.8 倍 的情况下,依然保持了19.4 fps的实时处理速度,消除了术中反馈的延迟,为医生提供即时、精准的视觉辅助。
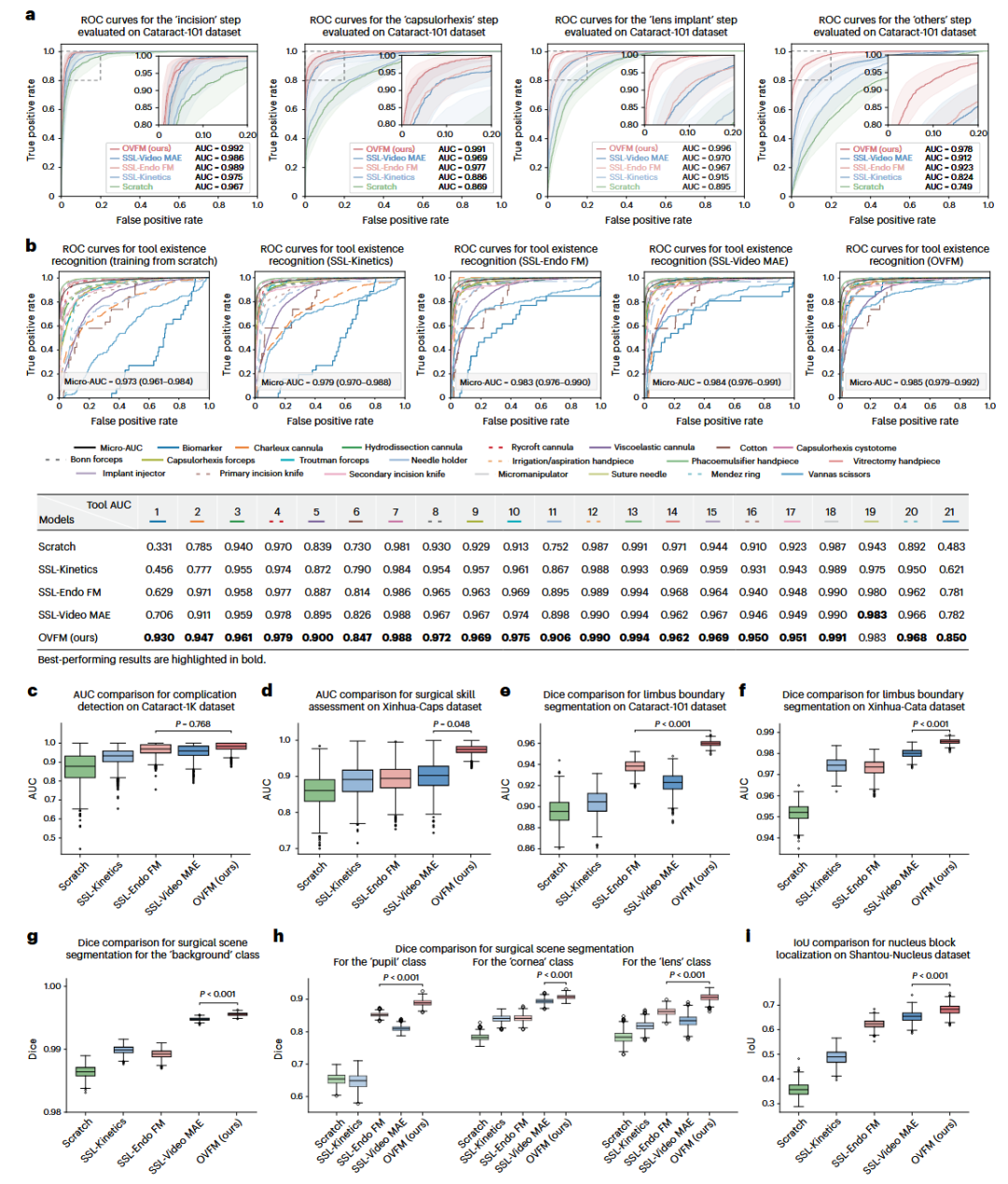
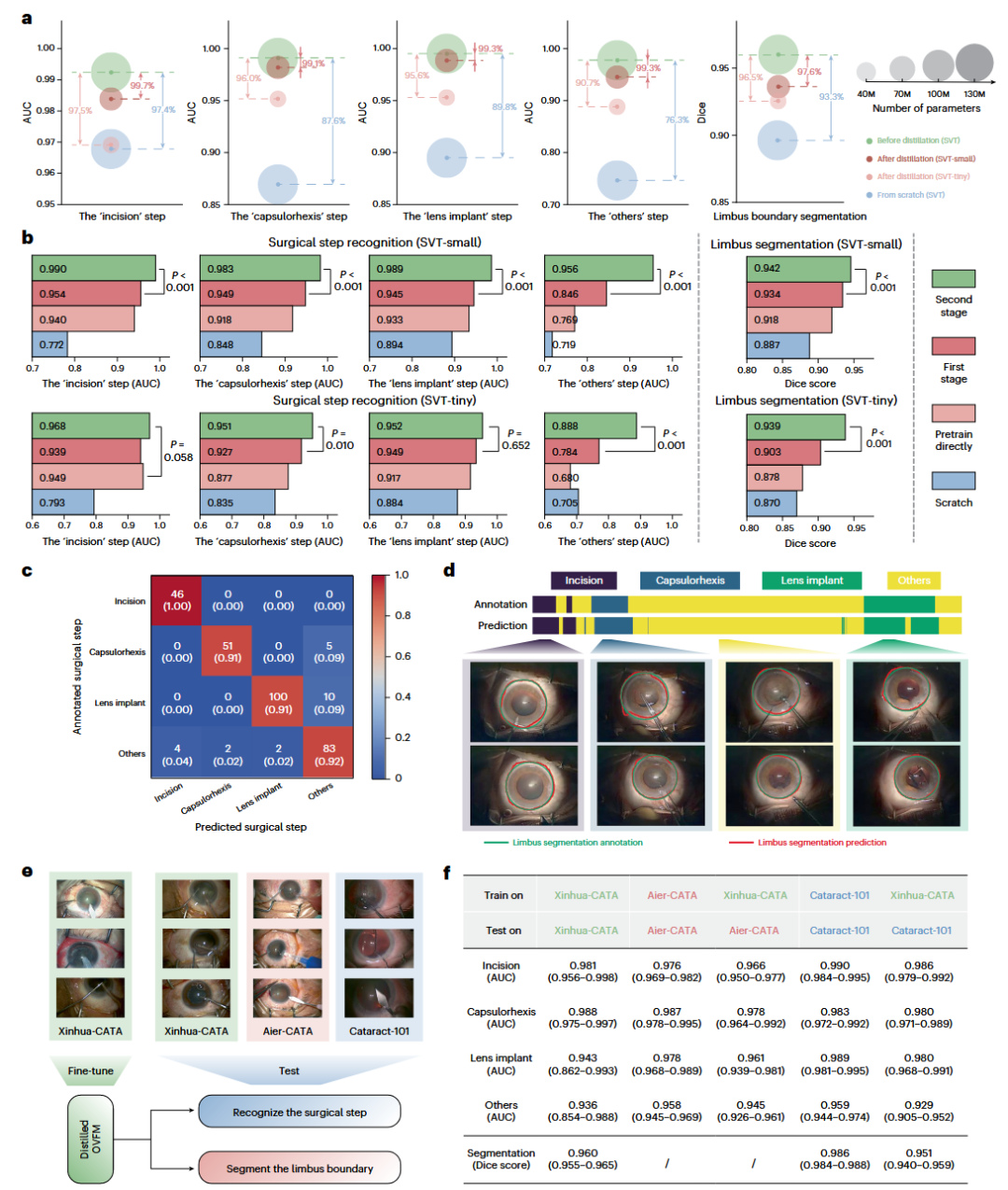
1、手术步骤识别:精准理解手术进程 OVFM在手术步骤识别任务中表现卓越。研究团队在Cataract-101、Xinhua-Cata、Aier-CATA三个数据集上评估了模型对白内障手术四个关键步骤(切口、撕囊、晶体植入、其他)的识别能力。在Cataract-101数据集上,OVFM的AUC分别达到:切口0.992、撕囊0.991、晶体植入0.996、其他0.978,显著优于对比模型(包括自然视频预训练的SVT、内窥镜预训练的SSL-Endo FM等)。即使在小模型版本(SVT-Tiny)下,模型仍能保留原模型90%以上的性能,且参数量减少15.8倍,为实时部署奠定了基础。 2、工具存在识别与并发症检测:捕捉精细操作细节 在CATARACTS数据集(22种手术工具)的工具存在识别任务中,OVFM的micro-AUC达到0.985,在21/22种工具上取得最佳结果,表明其能精准捕捉器械的细微运动特征。在Cataract-1K数据集的并发症检测(如瞳孔突然收缩)任务中,OVFM同样取得最优AUC(0.981),展现了其对异常事件的高度敏感性。 3、手术技能评估:反映医生水平差异 在Xinhua-Caps数据集的手术技能评估任务中,OVFM能够区分不同经验水平医生的操作差异,AUC达0.972,显著优于其他模型。这表明OVFM学到了与医生技能相关的时序模式。 4、解剖结构分割:精准定位手术关键区域 在角巩膜缘边界分割任务中,OVFM在Cataract-101数据集上Dice系数达到0.960,在Xinhua-Cata数据集上高达0.986,均显著优于对比模型。在手术场景分割任务中,OVFM对背景、瞳孔、角膜、晶状体等结构的Dice系数均超过0.88,展现出卓越的空间定位能力。 5、晶状体核块定位:精准识别目标区域 在Shantou-Nucleus数据集的核块定位任务中,OVFM的IoU达到0.682,显著超越其他模型,为后续术中导航提供了精准的解剖结构参考。 图 2 | OVFM 在下游任务中的性能评估。 a,在 Cataract-101 数据集(n = 28 段视频)上进行手术步骤识别的 ROC 曲线。实线显示完整测试集的经验 ROC 曲线;阴影区域表示 95% Bootstrap 置信区间(CIs)。b,在 CATARACTS 数据集(n = 25 段视频)上进行手术器械存在识别的 ROC 曲线。下方表格总结了各模型对每种器械识别的 AUC 值。c,Cataract-1k 数据集(n = 49 段视频)上并发症检测的 AUC 对比。d,Xinhua-Caps 数据集(n = 82 段视频)上手术技能评估的 AUC 对比。e, f,Cataract-101 数据集(e,n = 28 段视频)和 Xinhua-Cata 数据集(f,n = 23 段视频)上角膜缘边界分割的 Dice 分数对比。g, h,Cataract-101 数据集(n = 10 段视频)上手术场景分割的 Dice 分数对比:分别针对背景类(g)以及瞳孔、角膜和晶状体类(h)。i,Shantou-Nucleus 数据集(n = 20 段视频)上晶体核块定位的 IoU 对比。箱线图总结了聚类 Bootstrap 迭代中的性能指标分布。中心线代表中位数,箱体跨度为四分位距(第 25 至 75 百分位数),须线延伸至 1.5 倍四分位距内的最小值和最大值。c-i 中的统计比较采用双侧配对聚类 Bootstrap 假设检验。 图 3 | OVFM 蒸馏性能评估。 a,各版本 OVFM 模型在四个手术步骤(AUC)和角膜缘边界分割(Dice)上的性能对比:包括蒸馏前(SVT)、蒸馏后(SVT-small 和 SVT-tiny)以及从头训练(from scratch)的版本。标记的大小反映了模型的参数量。b,评估两阶段蒸馏过程的消融实验。统计比较采用双侧配对聚类 Bootstrap 假设检验。c,部署蒸馏后的 OVFM 后,针对回顾性临床视频案例的手术步骤识别混淆矩阵。d,回顾性临床案例的手术步骤识别(顶部)和角膜缘边界分割(底部)的定性结果。彩色条显示了预测手术步骤与标注真值(ground truth)的一致性。角膜缘边界分割图像中,红色线为预测边界,绿色线为原始视频帧上的标注真值。e,使用三个不同数据集进行跨中心验证的示意图。f,跨中心验证结果。斜线(/)表示不适用。
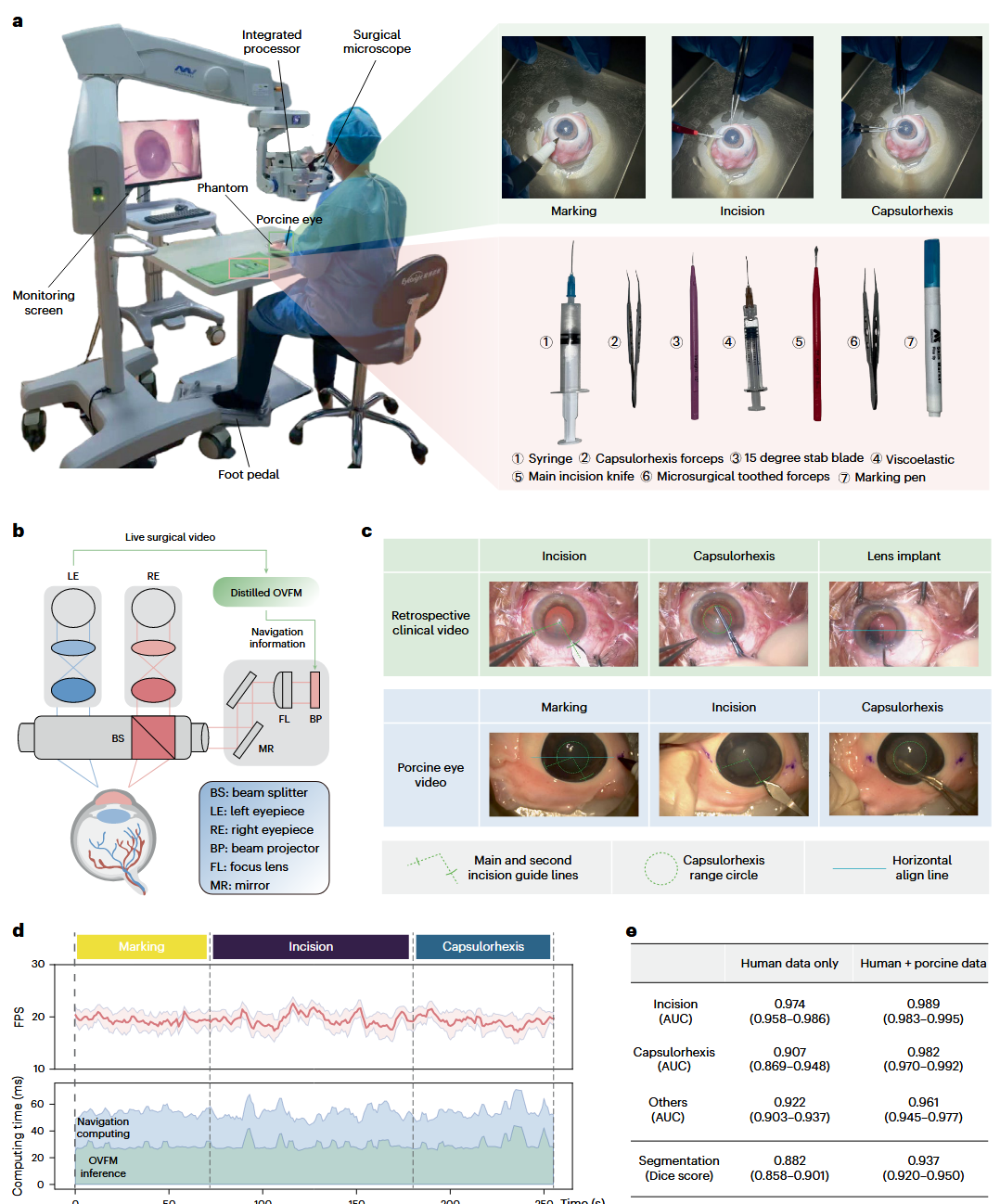
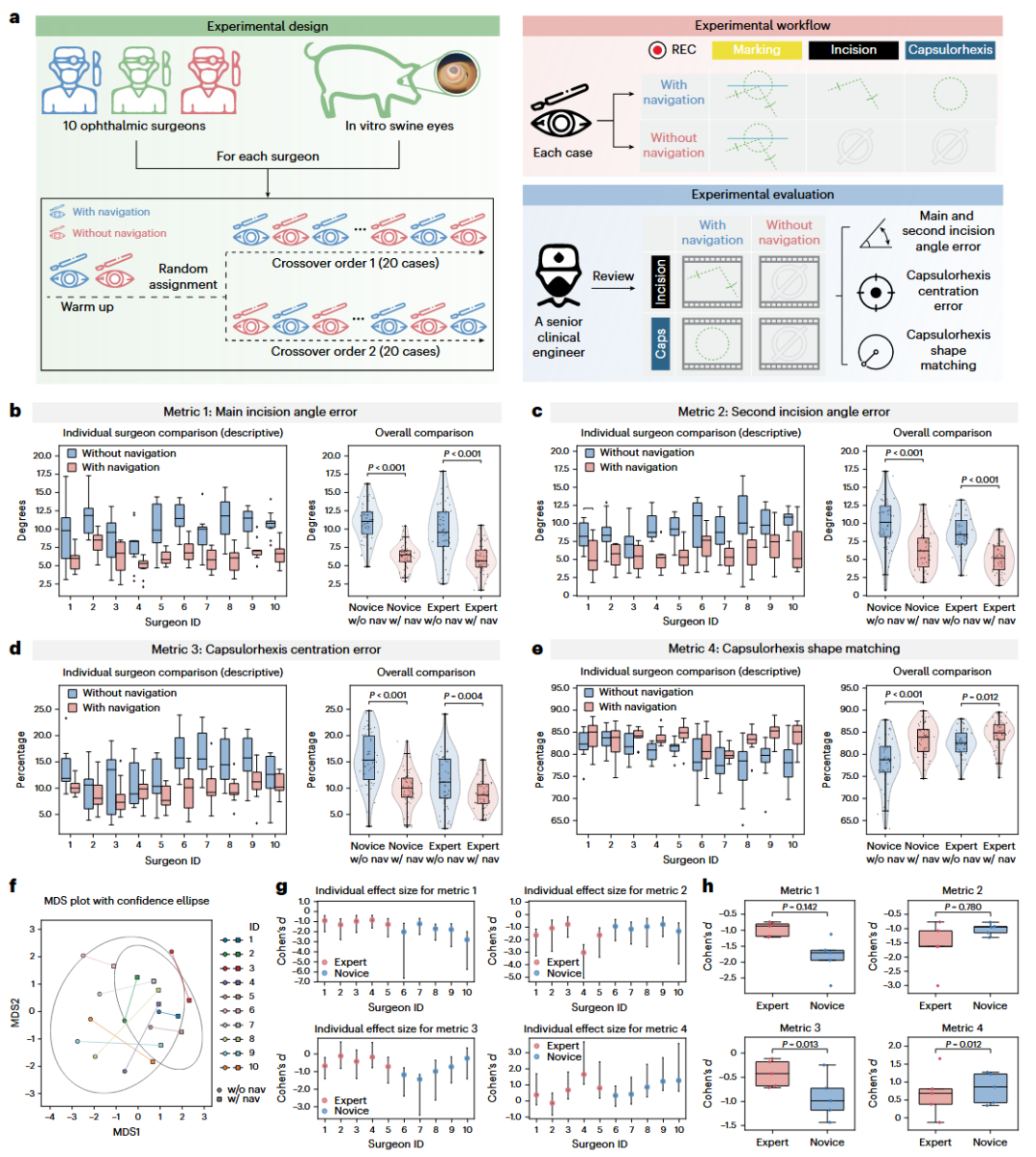
研究最具突破性的部分在于其术中智能导航系统的实战表现。通过将 distilled OVFM 集成到手术显微镜,系统可以实时识别手术步骤并动态投射引导线(如最佳切口位置、撕囊参考圆环)。 实时性能:将蒸馏后的OVFM部署到手术显微镜原型机后,系统平均处理帧率达到19.4 fps,计算延迟稳定,能够满足术中实时导航需求。 猪眼手术验证:研究团队邀请10名不同经验水平的眼科医生,在猪眼上进行白内障手术,采用交叉设计(有/无导航辅助),评估导航系统对手术表现的影响。 技能提升:有导航时,主切口角度误差显著降低(P < 0.001),第二切口角度误差同样显著改善;撕囊中心偏离误差减小,撕囊形状匹配度提高。 经验差距缩小:新手医生在导航辅助下获益最大,各项指标改善幅度显著高于专家医生,多维缩放(MDS)分析显示,有导航时所有医生的手术表现更集中、一致性更高。 实时交互:医生无需手动切换模式,系统能自动感知进度并提供“步进式”指引,实现了真正意义上的术中人机协同。 图 4 | OVFM 与手术显微镜的集成。 a,在离体猪眼白内障手术实验中,集成 OVFM 的手术显微镜装置。b,OVFM 驱动显微镜的光路示意图。导航信息由蒸馏后的 OVFM 计算,并通过光束投影仪和分束器投射给医生。c,回顾性临床视频和猪眼手术中的 OVFM 引导导航场景。d,标记、切口和撕囊步骤中的实时性能:显示了 FPS 变化(顶部)以及 OVFM 推理和导航处理的计算时间(底部)。阴影区域表示使用移动平均法(窗口大小 = 3)处理后的平滑耗时信号。e,OVFM 在结合数据集(“人眼 + 猪眼数据”)与仅在人眼手术视频(“仅人眼数据”)上微调结果的对比。 图 5 | 使用 OVFM 驱动的手术显微镜进行的离体猪眼用户研究。 a,交叉用户研究(Crossover user study)的设计与流程。b–e,针对四项手术性能指标对导航辅助进行的定量评估:主切口角度误差(b)、侧切口角度误差(c)、撕囊居中误差(d)和撕囊形状匹配度(e)。针对每项指标,左侧箱线图显示了每位医生的对比(n = 10 例),右侧显示了基于专业程度(初学者 vs 专家)和导航条件(有导航 vs 无导航)的分组对比(n = 100 例)。f,手术性能指标的多维尺度分析(MDS)图。每个点代表一位医生在特定条件下的综合表现。椭圆代表各条件的 95% 置信区间。g,每位医生各项指标的效应量(Cohen’s d,n = 10 对试验),对比有无导航时的表现,按专业水平分组。横条代表通过配对差异计算的百分位 Bootstrap 95% 置信区间(2,000 次重采样)。h,初学者与专家组之间效应量的组间对比(每组 n = 5 位医生;每位医生的 Cohen’s d 由 n = 10 对试验计算)。nav:导航。在 b-e 和 h 中,箱线图代表数据分布。中心线为中位数,箱体为四分位距,须线为 1.5 倍四分位距内的极值。差异评估采用线性混合效应模型。统计显著性通过相关固定效应项的双侧 Wald 检验进行评估。 本研究首次将视频基础模型应用于眼科手术领域,通过大规模自监督预训练和两阶段知识蒸馏,构建了既能理解复杂手术动态、又能实时部署于手术显微镜的OVFM模型。在猪眼白内障手术中,OVFM驱动的导航系统显著提升了医生手术表现,缩小了经验差距,为未来“AI辅助手术”的临床落地提供了可行路径。 主要创新点:构建了迄今最大规模、最多样化的眼科手术视频数据集(11,426部视频,144种手术类型);提出了自监督视频Transformer架构,学习通用时空特征,在7个下游任务上全面超越现有模型;首创了两阶段知识蒸馏策略,实现大模型到轻量模型的性能无损压缩,满足实时部署需求;首次将基础模型集成到手术显微镜并完成真实猪眼手术验证,证明其对提升手术技能的临床价值。 局限性:当前研究主要集中于白内障等前段手术,对后段手术的通用性仍需进一步验证;模型仅采用稀疏采样视频片段进行预训练,可能丢失部分精细时间信息;研究仅在猪眼上进行验证,距离真正进入临床还需要解决伦理、泛化、透明度等问题。 Tu, P., Zheng, C., Xie, X. et al. An ophthalmic video foundation model for surgical recognition and navigation with wet-lab porcine eye validation. Nat. Biomed. Eng (2026). https://doi.org/10.1038/s41551-026-01622-w
END 撰文 | 程虞茜 姜泽坤 排版 | 周宇茜 审核 | 医工学人理事会 扫码加入医工学人,进入综合及细分领域群聊, 参与线上线下交流活动
推荐阅读

点击关注医工学人

本篇文章来源于微信公众号: 医工学人
