






星标“医工学人”,第一时间获取医工交叉领域新闻动态~

结直肠癌是全球最常见的癌症之一,而结肠镜检查的质量直接决定了早期癌症的发现率。尽管AI已被证明是医生的得力助手,但其发展却长期受困于“数据饥饿”——去哪里寻找足够多、标注足够好的数据来“喂养”这些越来越庞大的模型?9月16日,一篇发表于《Nature biomedical engineering》的重磅研究给出了答案,由来自复旦大学、帝国理工学院、南京理工大学、香港科技大学等多所院校的研究团队合作完成,研究团队另辟蹊径,不再依赖于昂贵和缓慢的人工标注,而是开发出一种名为EndoKED的自动化数据挖掘引擎,巧妙地将大语言模型(LLM)和视觉基础模型(LVM)的能力结合起来,从海量的临床病历档案中自动标注。

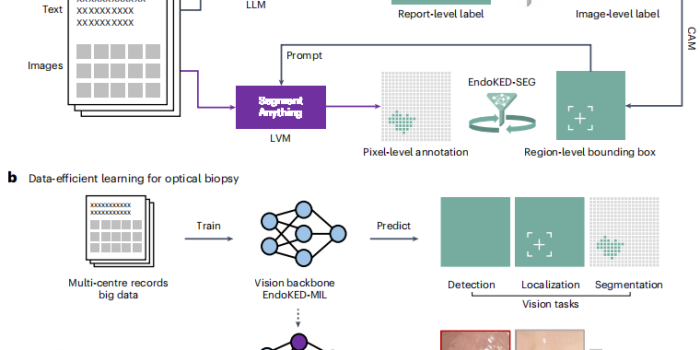
医院里堆积如山的结肠镜检查记录,每一份都包含着图像和医生书写的文字报告。这些是非结构化的原始数据,蕴含巨大价值但难以直接利用。EndoKED的工作流程就像一个高度智能的流水线:
-
首先,大语言模型(如同一个精通医学术语的阅读理解高手)上场,它快速阅读成千上万份结肠镜报告,准确地找出描述息肉的关键词句,比如“于乙状结肠见一5mm息肉,表面光滑”。
-
然后,语言模型将这些文本信息转化为给视觉模型的“指令”。视觉模型(如同一个像素级的图像识别专家)根据指令,在对应的结肠镜图片中锁定并精确圈出(即像素级分割)这颗5mm的息肉。
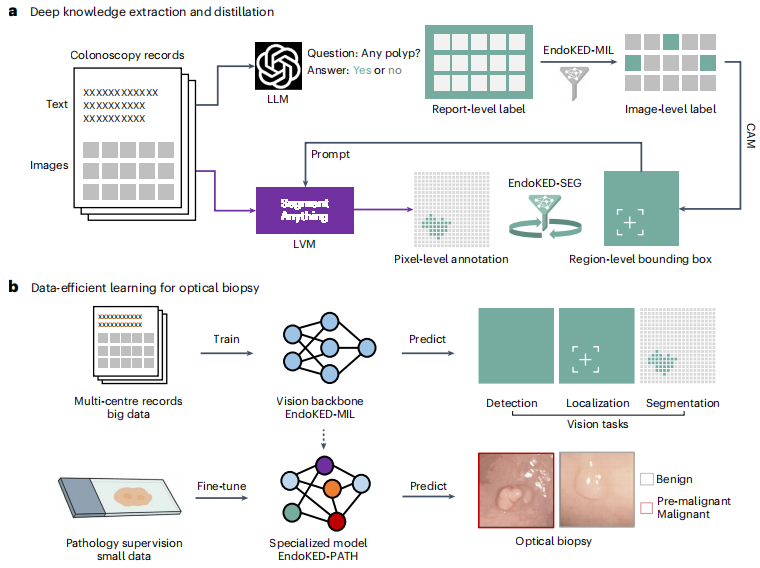
图1:EndoKED 设计概览及其在息肉诊断中的应用
通过这种“阅读-定位-标注”的全自动流程,EndoKED将尘封的临床数据转化为了可供AI模型训练的有效数据。研究人员利用这种方法,以前所未有的效率构建了一个庞大的、高质量的结肠镜图像标注数据库。
这不仅仅是自动化标注那么简单。更关键的一步是“知识蒸馏”。团队利用EndoKED产出的海量数据对下游的AI模型进行预训练。这个过程好比让一个学生在考试前做完了海量的、包含答案的模拟题库,使其对各种情况了然于胸。
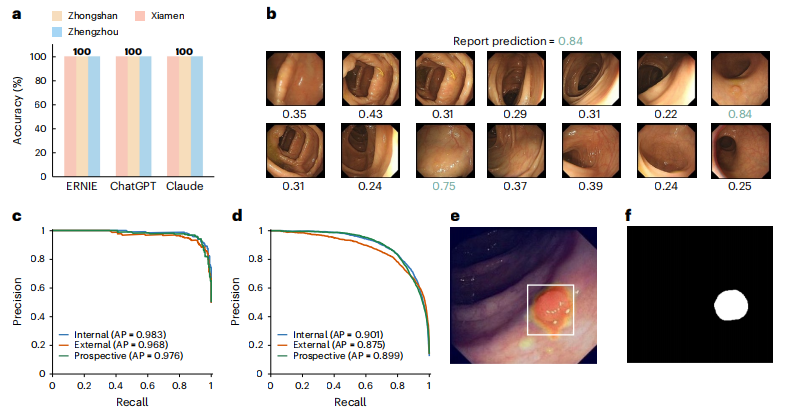
图2:EndoKED框架在报告摘要、图像级检测、像素级分割和模型预训练方面的性能
结果是惊人的。经过预训练的息肉分割模型,其准确性和泛化能力(即在不同医院、不同设备的数据上的表现)都达到了业界顶尖水平。更重要的是,这个强大的视觉基础模型在学习新技能时表现出极高效率。在“光学活检”(通过图像判断息肉是否为癌前病变)的任务中,仅用少量数据进行微调,其表现就足以媲美甚至超越经验丰富的内镜医生。
该研究中利用大语言和视觉模型进行知识提取的范式,在其他医疗领域已有诸多探索和应用。例如,在放射学中,类似技术被用于自动分析胸部X光片和CT扫描图像,并结合放射科医生的报告文本,自动生成诊断摘要或定位肺结节等病灶,极大地提高了阅片效率。在数字病理学领域,AI模型正在学习解读全切片图像(WSI),通过分析海量病理报告和图像数据,实现对癌细胞的自动识别、分级和计数,辅助病理医生做出更精准的诊断。这些应用的核心思想与EndoKED一致,都是通过多模态AI技术,将非结构化的图像和文本数据转化为结构化的、可用于临床决策支持的知识,旨在减轻医生负担,提升诊断的准确性和一致性。
这项研究的意义远不止于结肠镜检查。它为整个医学影像AI领域提供了一个强大的新范式:如何利用大型基础模型,将沉睡在医院信息系统中的海量真实世界数据,转化为驱动下一代精准医疗AI的核心燃料。 从放射影像到病理切片,EndoKED所展示的道路,或许将开启一个AI赋能精准医疗的全新时代。
[1] Wang, S., Zhu, Y., Yang, Z. et al. Leveraging large language and vision models for knowledge extraction from large-scale image–text colonoscopy records. Nat. Biomed. Eng (2025).
https://doi.org/10.1038/s41551-025-01500-x
END
编辑 | 郝娅婷
排版 | 周宇茜
审核 | 医工学人理事会
扫码加入医工学人,进入综合及细分领域群聊,
参与线上线下交流活动

推荐阅读
Light Sci. Appl. | 上交大 & 哈佛大学提出AI加持的下一代LED疗法:可穿戴或将成为植入人体的“智能诊疗师”
点击关注医工学人

本篇文章来源于微信公众号: 医工学人
