






星标“医工学人”,第一时间获取医工交叉领域新闻动态~

超声检查是高度依赖操作者经验的影像学 modality。一名新手超声医师成长为专家,需要数年时间积累“手感”与“眼力”。2026年1月15日,牛津大学团队在《Nature Biomedical Engineering》上发表的研究,给出了一个激进的解决方案:他们训练出一个名为Sonomate的视觉语言模型,能够实时“看懂”超声视频流,理解操作者的口语指令,并在无需人工标注的前提下完成解剖结构识别、图像质控、操作序列追踪等任务。在关键指标上,Sonomate将新手与资深医师的技能差距缩小了15.4%。这不仅是医学影像AI从“读图”走向“读视频、懂对话”的技术跨越,更可能成为缓解全球超声医师短缺困境的拐点。

超声检查有一个被长期默许却又代价高昂的悖论:它既是最普及的影像技术,也是最依赖“手感”的技术。
与CT、MRI不同,超声是实时、动态、自由手的操作过程。探头角度、施压力度、切面选择,每一个决策都直接影响图像质量和诊断准确性。一名刚取得资质的超声医师与资深专家之间的差距,核心不在于“读不懂图”,而在于“扫不出图”——缺乏对解剖结构快速定位、标准平面即时判断、异常征象敏锐捕捉的“肌肉记忆”。
这种技能鸿沟正在演变为全球性的医疗资源危机。在发达国家,超声检查需求持续增长,而资深医师培养周期长达5—10年;在中低收入国家,合格的超声从业者缺口数以万计。传统解决方案——延长培训周期、增加模拟训练——边际效应递减,难以规模化复制“专家经验”。
现有的人工智能辅助方案同样存在结构性缺陷:
通用视觉语言模型(如CLIP):无法适配医学场景。胎儿超声图像中的“头”与自然图像中的“头”形态天差地别,CLIP在胎儿解剖分类任务上的召回率仅13.3%,基本不具备可用性。
医学多模态模型(如BiomedCLIP、Med-Flamingo):虽在医学图像-报告匹配上表现优异,但其训练语料来源于学术论文的书面语,与超声医师在操作现场的口语指令存在显著差异。更关键的是,这些模型仅能处理静态图像,无法理解超声扫查的视频流时序逻辑——而后者恰恰是操作技能的核心载体。
核心困境:我们需要一个既“懂超声图像”又“懂超声语言”,且能在实时操作中提供反馈的AI。但现实是,训练这样的模型需要海量的、成对的超声视频与操作者语音数据,且要应对口语的随意性、内容与画面的时间错位、不同医师的习惯差异——这些“脏数据”恰恰被学术界长期回避。
Sonomate的突破性,在于它不是在一个“干净”的人造数据集上训练,而是在真实的临床超声操作现场“浸泡”出来的。
研究团队依托PULSE项目,采集了525段全流程胎儿超声扫查视频,时长总计151小时,涵盖早、中、晚孕期。同步录制操作医师的语音,经WhisperX转录为79,885条句子,平均句长9.24词。这一数据集的独特性在于:它记录的不是“事后报告”,而是“边操作边口述”的真实思维流。
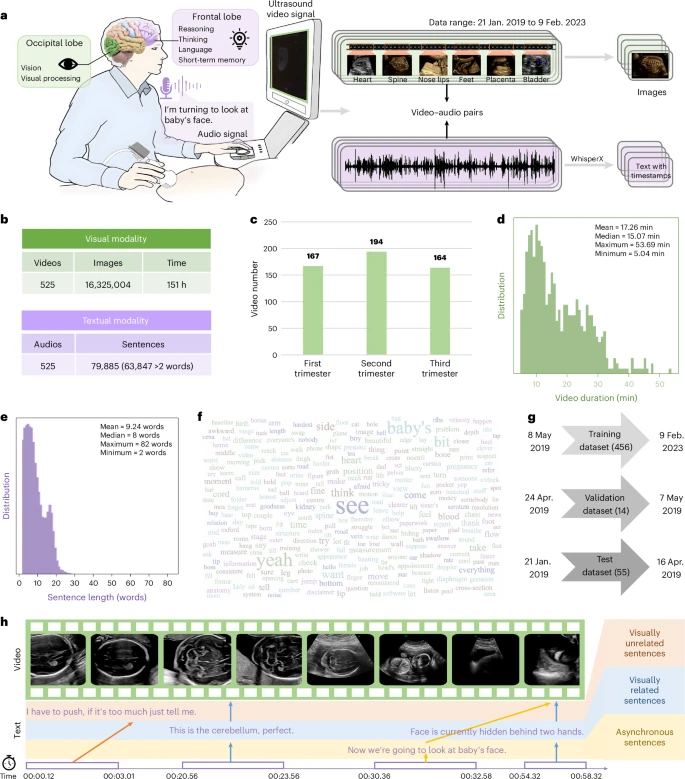
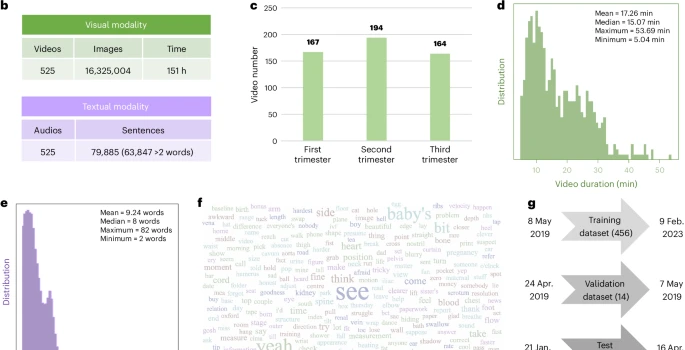
图1:数据集概览。
a,超声视频–音频对的采集与预处理。
b,所采集的视觉与文本模态数据总量。
c,妊娠早期、中期及晚期扫描的分布。
d,视频时长的分布。
e,每句词数的分布。
f,本数据集的词云。
g,按采集时间划分的训练集、验证集与测试集。
h,临床超声视频中一个视觉–文本错位的示例。
面对这一数据,Sonomate的核心技术创新可概括为三层对齐架构:
|
技术层级 |
传统方法困境 |
Sonomate解决方案 |
性能提升证据 |
|
粗粒度对齐 (视频-文本) |
整段视频与整段转录强制对齐,口语中大量“与患者寒暄”内容成为噪声 |
对比学习:拉近成对视频-文本距离,推远不成对样本 |
为细粒度对齐奠定基础 |
|
细粒度对齐 (帧-句子) |
语音与画面天然不同步——医师先说“我们看股骨”,几秒后才切到股骨平面 |
上下文标签校正:将当前句子与之后2帧关联为正样本 |
相似度矩阵更贴近真实对齐标签 |
|
语义噪声过滤 (解剖意识对齐) |
每3句话中仅有1句与视觉内容相关(图1h) |
构建超声视觉词汇表(Extended Data Table 1),提取句中的解剖关键词生成模板句 |
去除弱关联词汇后性能轻微下降,去除强关联词汇后性能断崖式下跌 |
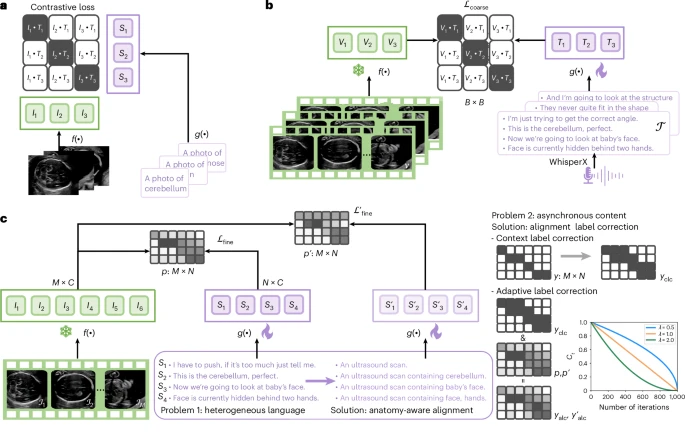
图2:数据集概览。
a,CLIP²² 示意图。
b,粗粒度视频–文本对齐方法将配对的视频与文本(即转录音频)特征“拉近”,同时将未配对的特征“推远”。
c,细粒度帧–句子对齐方法通过优化文本–视觉相似度矩阵 p(⋅)p(⋅),最大化句子与其对应视频帧之间的相似度得分。
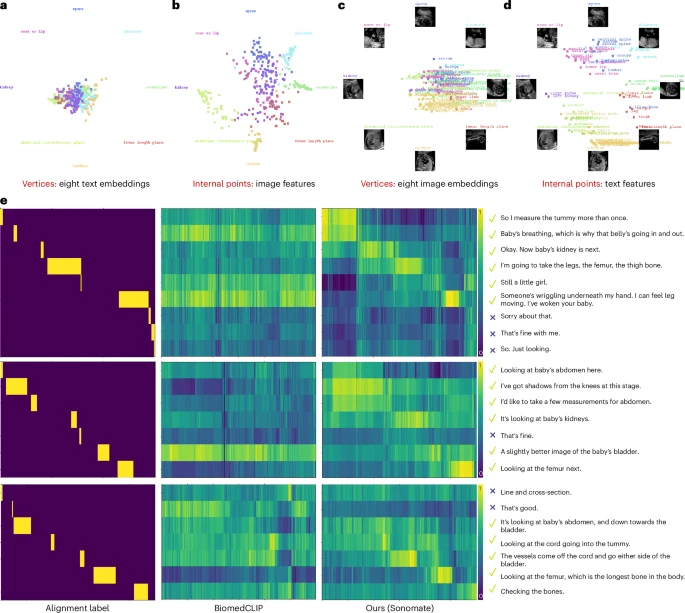
图3:跨模态对齐可视化。
a,BiomedCLIP²³ 的图像特征可视化。
b,本文 Sonomate 的图像特征可视化。
c,BiomedCLIP²³ 的文本特征可视化。
d,本文 Sonomate 的文本特征可视化。
e,BiomedCLIP 与本文方法所得文本–视觉相似度矩阵 p 的对比。采用 Sigmoid 激活函数将相似度得分归一化至 [0,1]区间,即σ(p)。x 轴表示视频帧索引,y 轴按序排列句子。在 a–d 中,顶点与内点间距离越小,表明跨模态对齐效果越佳。在 e 中,相似度矩阵 p 与对齐标签匹配程度越高,反映跨模态对齐性能越优。
这一架构的本质,是让模型学会“选择性倾听”。Sonomate不试图理解医师说出的每一个词,而是精准捕捉那些与画面内容强关联的“操作指令词”,并容忍数秒的时延。这是对人类超声扫查认知过程的高度仿真。
Sonomate的有效性在三类下游任务中得到系统验证,其关键数据具有显著的临床与技术意义。
1. 零样本解剖分类:超越监督学习范式
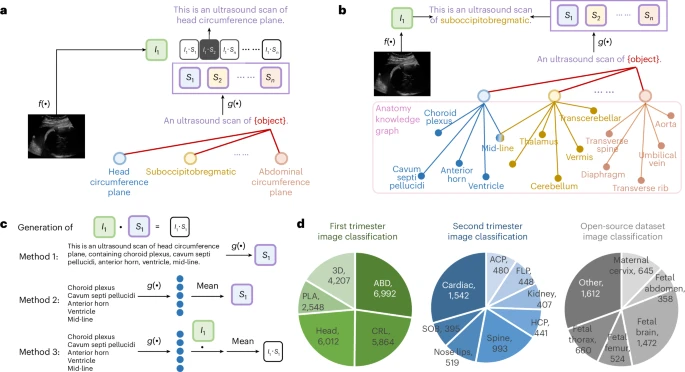
图4:解剖结构检测流程与数据集。
a,CLIP²² 的推理流程。
b,本文知识增强型解剖结构检测流程。
c,从解剖知识图谱中获取信息的三种方案。
d,解剖结构检测验证数据集的统计信息与实验结果。
ABD,腹部;PLA,胎盘;CRL,头臀长平面;ACP,腹围平面;FLP,股骨长平面;HCP,头围平面;SOB,枕下前囟平面。
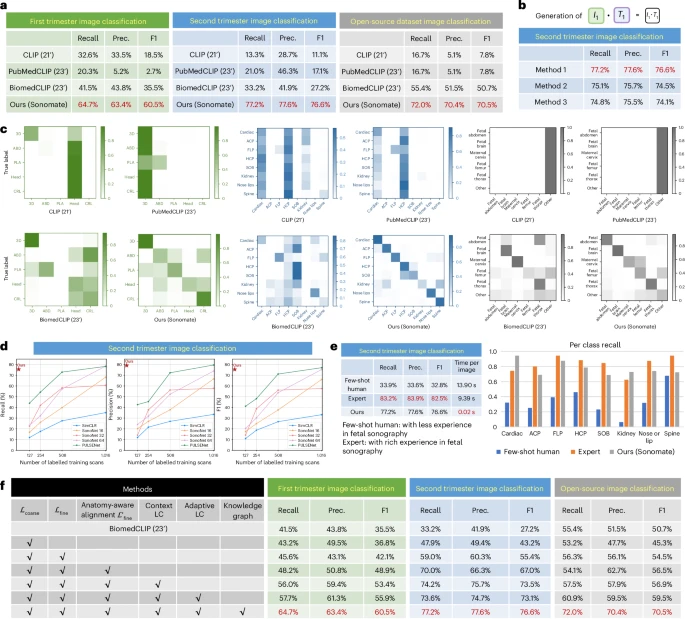
图5:解剖结构检测性能。
a,在妊娠早期数据、妊娠中期数据及开源母胎超声数据集上的解剖结构分类性能。
b,解剖知识图谱中三种信息获取方案的对比。
c,混淆矩阵。颜色条对应于混淆矩阵中的数值。
d,与现有全监督基线模型的性能对比。
e,与人类操作者水平的对比。
f,消融研究。最佳结果以粗体红色字体突出显示。Prec.,精确率;F1,F1分数;LC,标签校正。
Sonomate在无需任何人工标注数据的前提下,在孕早期5类、孕中期8类、以及外部公开数据集的6类解剖图像分类任务中,召回率达到77.2%,而CLIP仅13.3%、BiomedCLIP仅33.2%。更值得注意的是:
在标注训练数据少于1000例的条件下,Sonomate的识别准确率超过全监督模型SonoNet和SimCLR;
在资深医师与新手医师数据分别训练的对比中,用新手操作数据训练的Sonomate,其性能与资深医师训练版的差距较基线缩小15.4%(Extended Data Fig. 2)——这是技能迁移的量化证据。
2.图像级视觉问答:精度与鲁棒性
Sonomate在5类图像级VQA任务中平均准确率84.15%,较BiomedCLIP基线提升6.3%—15.7%。更具工程价值的是其护栏机制:
OOD检测:在阈值0.97时可100%拒绝非分布内问题;
拼写容忍:对“fetal”误拼为“fetal”等输入,经改写后准确率从75.28%恢复至79.78%。
3.视频级问答:首个“懂时序”的超声模型
这是当前医学影像语言模型中极少数支持视频级推理的工作。Sonomate能够回答“操作者依次检查了哪些解剖结构”“下肢检查完后看了什么”“是否漏扫了某个切面”等时序逻辑问题。在解剖序列预测任务中,将最小编辑距离(MED)降低0.03,BLEU-1提升0.03。
4.计算效率:可部署性验证
在GPU+CPU配置下,单张图像推理7.91ms,单问题回答7.737ms,4分钟超声视频的问题响应9.3秒。无需云端算力,可在常规工作站运行。

图6:基于知识的视觉(图像级与视频级)问答任务
a,本文基于知识的 VQA 流程。
b,图像级与视频级 VQA 数据集的统计信息,包括训练集、验证集和测试集的样本数量。
c,图像级 VQA 任务的实验结果。
d,视频级 VQA 任务的实验结果。注:最佳结果以粗体红色字体突出显示。
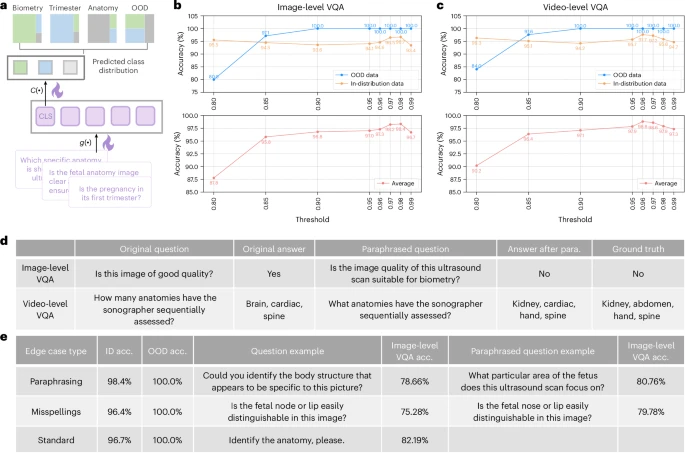
图7:Sonomate 的安全护栏。
a,OOD 问题检测网络。
b,图像级 VQA 任务的 OOD 检测准确率。
c,视频级 VQA 任务的 OOD 检测准确率。
d,问题释义的定性结果。
e,基于问题边缘案例的安全护栏验证。
para.,释义;acc.,准确率。
Sonomate的价值,并非在于“做出一个性能更好的分类器”,而在于重新定义了AI在超声临床工作中的生态位。
短期影响:超声培训的“副驾”
当前超声医师培训的核心痛点在于反馈的滞后性——学员扫查时无人即时纠错,事后回顾又丢失了操作情境。Sonomate可部署于超声设备端,在学员扫查时实时回答“这是标准平面吗”“漏了什么结构”,将专家经验嵌入操作流程,而非游离于报告环节。
中期影响:工作流效率的重构
研究中记录了一个典型场景:新手医师常因不确定第一张图像是否合格,连续拍摄多张冗余图像。这不仅延长检查时间,更增加患者暴露时间。Sonomate可在扫查瞬间给出“图像质量合格、可继续”的确认,预计可减少15%—20%的非必要图像采集。
长期影响:超声服务可及性的普惠化
在中低收入国家,资深超声医师极度稀缺。Sonomate提供了一条“技能压缩”路径:将资深医师数十年的经验模式化为可部署的模型,使基层医师在有限培训下达到更高质量的扫查水平。这是超声领域的“知识蒸馏”。
核心论断:“Sonomate并非旨在取代专家判断或进行临床诊断。其主要价值在于教育与早期职业支持——增强信心、辅助决策、提升流程效率、减少对资深医师监督的依赖。”(原文Discussion)
Sonomate是一项具备范式迁移潜力的研究,但将其从论文推向临床,仍需跨越三重门槛:
其一,数据集的地理与人口偏倚。 全部数据采集自英国牛津郡的单一医疗系统,操作者仅7名,患者均为英国本土孕妇。模型对非高加索人种胎儿解剖结构、不同品牌超声设备、非英语操作语音的泛化能力,尚未得到验证。
其二,“知识噪声”的鲁棒性。 研究坦诚指出,Sonomate在引入外部知识图谱后性能显著提升,但对训练时未见过的“噪声知识”高度敏感。在真实临床环境中,若接入的百科知识存在错误或与本地指南冲突,模型可能产生“自信的错误”。
其三,临床终点验证缺失。 当前所有性能指标均停留在图像/视频理解层面,尚未建立与患者结局改善、检查时间缩短、漏诊率降低等临床终点的关联。AI辅助是否真的能让患者受益,是产业化前必须回答的问题。
最后,也是最根本的隐忧:当我们将“资深医师的操作经验”蒸馏为模型参数,并大规模部署给新手时,我们是在加速技能普及,还是在削弱临床学徒制中不可替代的隐性知识传承?这是一个超越了技术范畴的命题,但恰恰是《麻省理工科技评论》读者应当保持警觉的。
[1] Guo, X., Alsharid, M., Zhao, H. et al. A visually grounded language model for fetal ultrasound understanding. Nat. Biomed. Eng (2026). END 撰文 | 郝娅婷 排版 | 张艳青 审核 | 医工学人理事会
https://doi.org/10.1038/s41551-025-01578-3
扫码加入医工学人,进入综合及细分领域群聊,
参与线上线下交流活动

推荐阅读
Nature Sensors | 美国西北大学新研究,贴片就能测压力:集成电致变色“时钟”的汗液芯片,如何开启持续激素监测新范式?
npj flexible electronics | 柔性纤维电极:韩国团队实现抗弯抗洗、可同时监测多部位的无源织物传感
npj Biomedical Innovations | 一台便携式EEG-TMS融合设备,双重干预:复旦团队「磁神经环」如何打通卒中康复的诊断与治疗闭环?
点击关注医工学人
本篇文章来源于微信公众号: 医工学人
