






星标“医工学人”,第一时间获取医工交叉领域新闻动态~

三维(3D)医学成像(如 CT 和 MRI)相比二维成像能提供更详尽的患者健康视图,但受限于公开配对数据集的匮乏,3D 影像 AI 的发展相对滞后。现有的 3D 模型多依赖小规模或无文本配对的数据,难以构建通用的基础模型。
近期,来自苏黎世大学、伊斯坦布尔 Medipol 大学等科研团队在《Nature Biomedical Engineering》发表了题为《Generalist foundation models from a multimodal dataset for 3D computed tomography》的研究,发布了CT-RATE数据集,并提出了首个基于胸部CT的视觉-语言预训练框架CT-CLIP及通用AI助手CT-CHAT。该研究通过开源大规模配对数据与基础模型,解决了3D医学影像领域数据稀缺的痛点,为构建通用型3D临床AI奠定了技术基础。
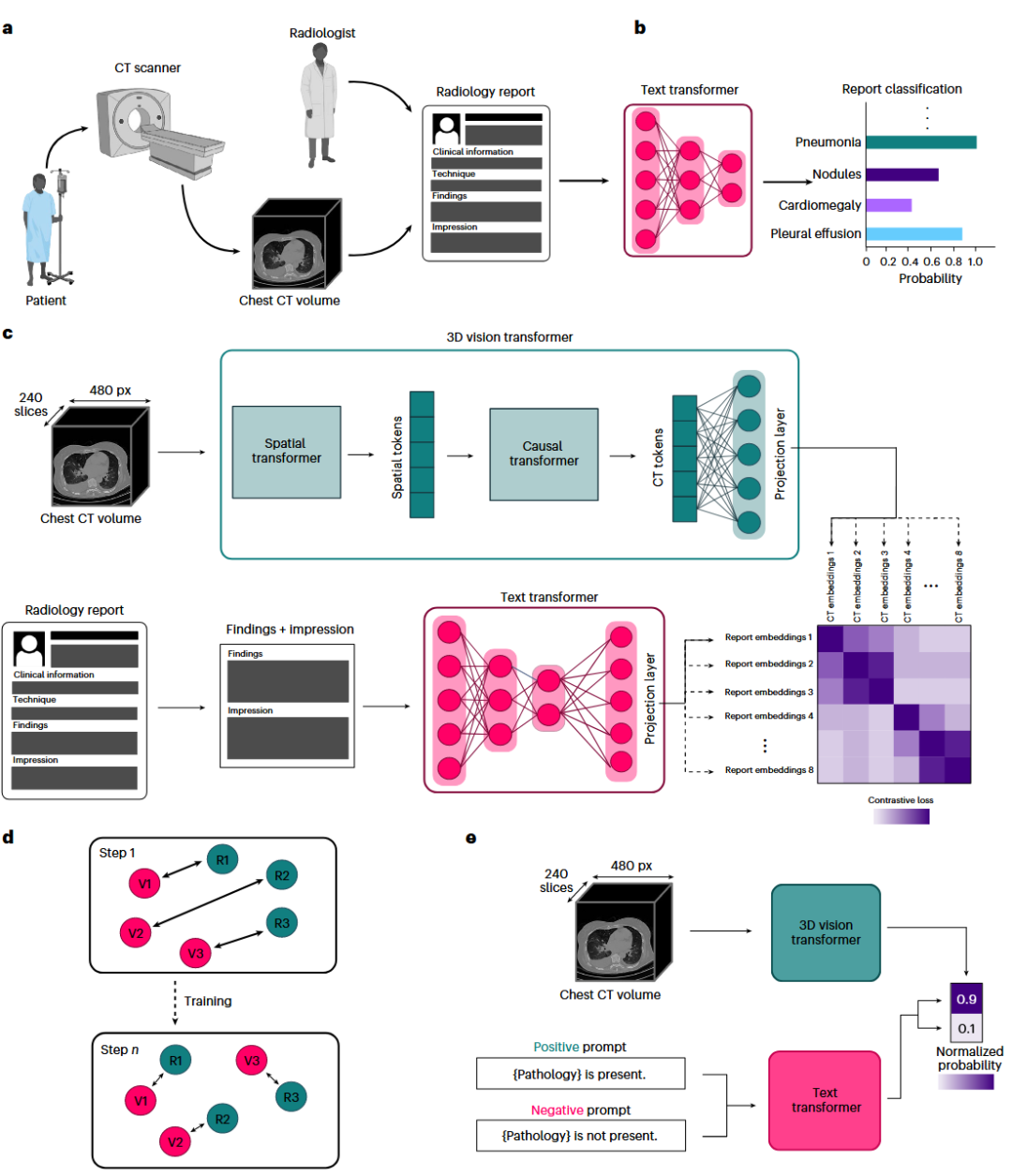
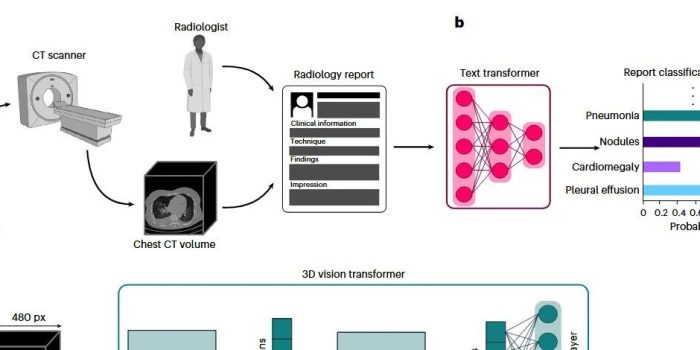
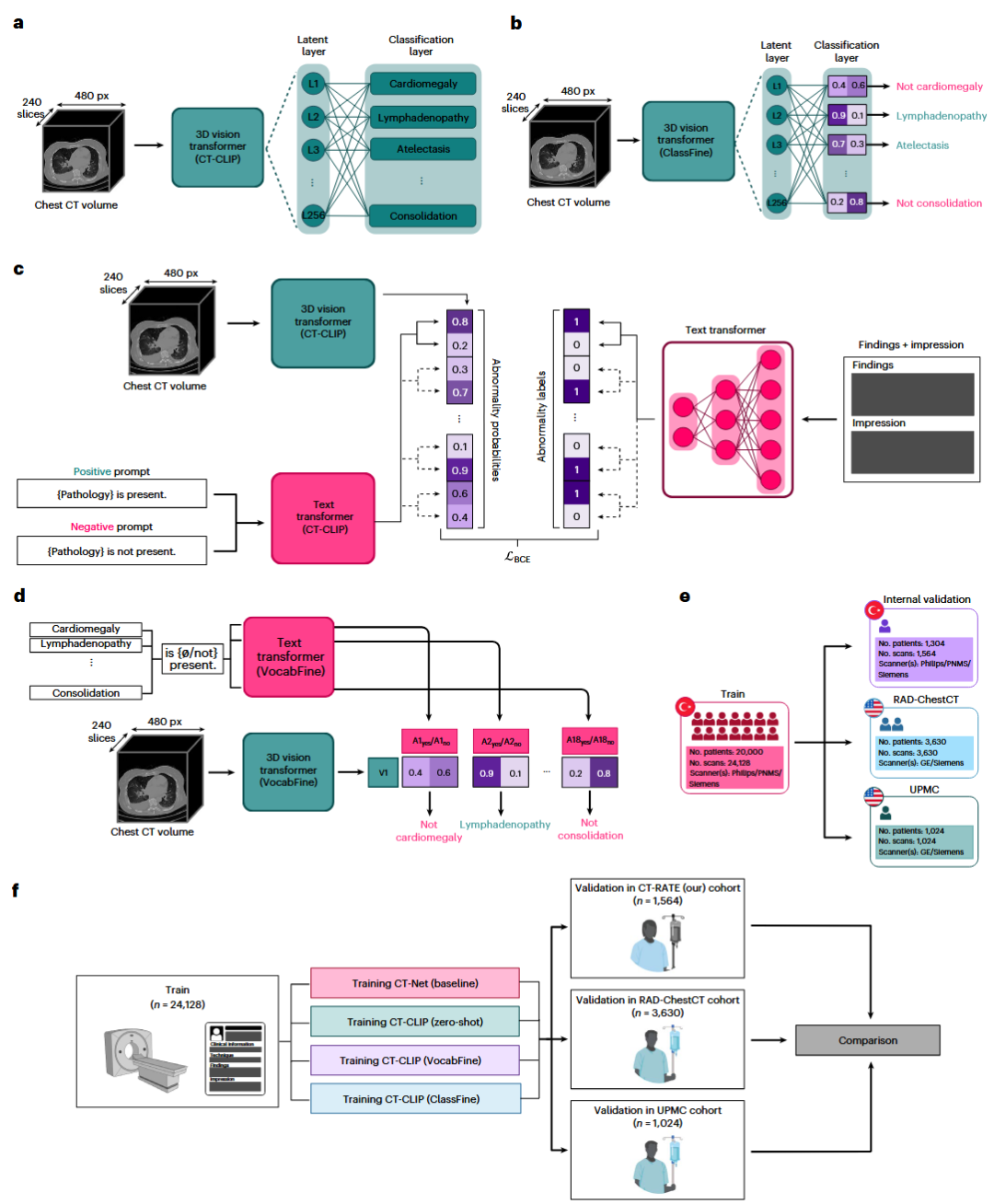
图 1 | 数据集概览与CT-CLIP框架。
a,CT-RATE数据集的采集协议,包含非增强3D胸部CT体积及放射科医生撰写的对应放射学报告。b,利用微调后的文本编码器从放射学报告中自动提取多异常标签(multi-abnormality labels)。c,CT-CLIP框架的训练过程:通过对比学习(contrastive learning)方法将3D胸部CT体积与来自CT-RATE的放射学报告进行配对训练。d,对比学习过程示意图,用于训练中的相关性矩阵,以确保精准的匹配识别与非匹配区分。表示体积嵌入,表示报告嵌入。e,零样本多异常检测(zero-shot multi-abnormality detection)的推理过程,使用正向和负向提示词(prompts)的Softmax归一化概率。
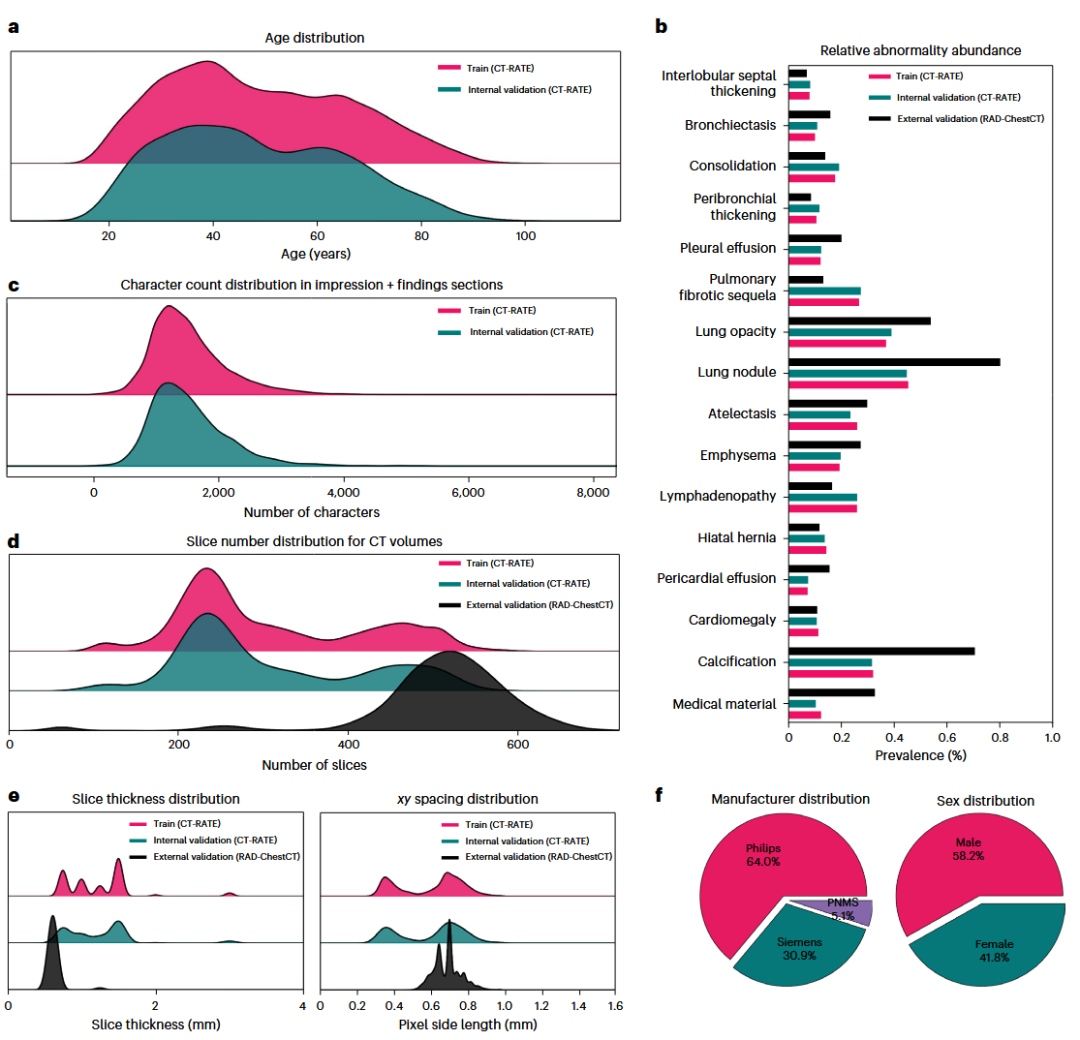
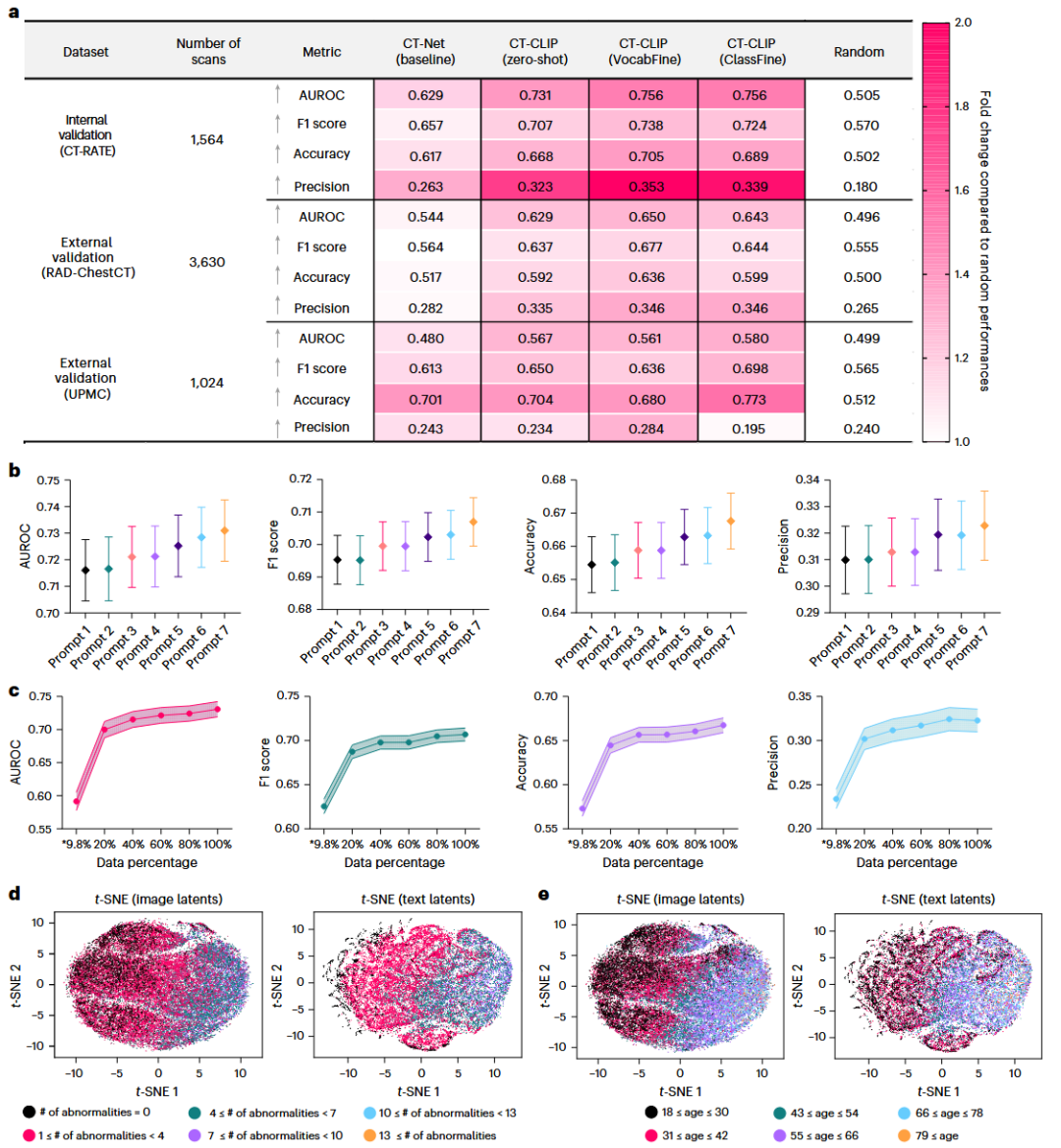
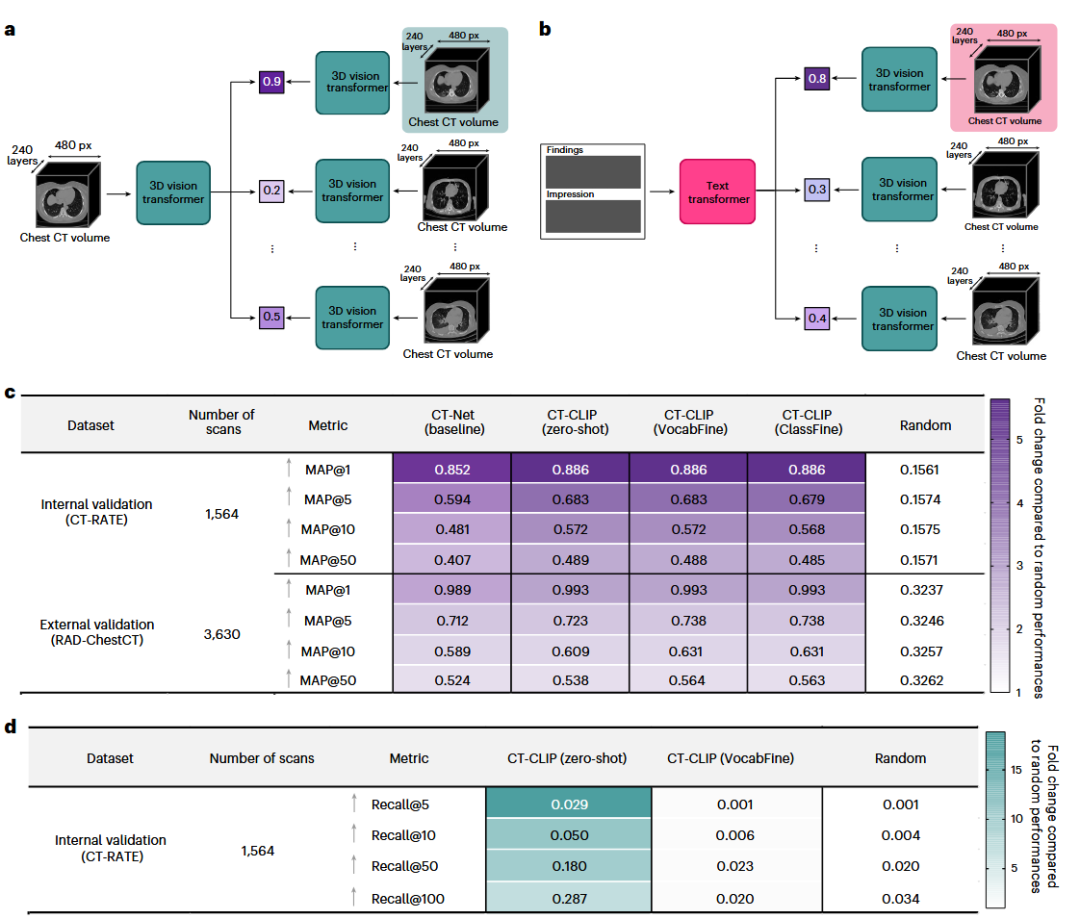
3D医学成像AI的核心挑战在于缺乏大规模的“影像-文本”配对数据。传统的监督学习需要昂贵的人工标注,且受限于预定义类别,难以适应复杂的临床需求。 研究团队为此构建了CT-RATE数据集,这是目前首个公开的、包含21,304名患者的25,692次非增强胸部CT扫描(重建后共50,188个3D体积)及其对应放射学报告的数据集。数据并非来自单一的精选实验环境,而是涵盖了真实临床场景中的多样性(年龄跨度18-102岁,涵盖Siemens、Philips等多种扫描设备,不同的切片厚度和重建算法),反映了以异质性为特征的现实世界场景。 架构上,研究团队开发了CT-CLIP(Chest CT-focused Contrastive Language-Image Pretraining)。该模型利用CT-ViT作为视觉编码器,CXR-Bert作为文本编码器,通过对比学习(Contrastive Learning)将3D CT影像与放射学报告映射到统一的语义空间。这使得模型能够在无监督情况下理解影像语义。 在此基础上,团队进一步开发了CT-CHAT。这是一个针对3D胸部CT的视觉-语言对话模型,结合了CT-CLIP的视觉编码器与Llama3.1大语言模型。通过在270万个问答对(VQA)上进行微调,CT-CHAT实现了对3D体积的深度理解和交互式诊断。这种灵活性使CT-CHAT成为增强放射科医生工作流程、减少判读所需的时间和精力以及提高3D医学成像诊断准确性的强大工具。 图 2 | 新型CT-RATE数据集的综合分析。 a,CT-RATE包含来自21,304名唯一患者的数据,年龄跨度为18至102岁。b,用于验证和微调目的,从每个CT体积的对应放射学报告中提取了18种不同异常的标签。c,CT-CLIP模型的训练过程使用了放射学报告的“印象(impression)”和“发现(findings)”部分,其字符长度各不相同,并与胸部CT体积配对。d,CT-RATE中胸部CT体积的切片数量范围为100至600层。e,x、y和z轴的间距(spacing)在不同体积间存在差异;所有胸部CT体积在训练前均经过预处理以确保间距一致。f,尽管源自单一机构,CT-RATE包含了使用三种不同制造商(Philips, Siemens, PNMS)的扫描仪获取的体积,确保了数据的多样性。 1) 零样本多异常检测(Zero-shot Multi-abnormality Detection) CT-CLIP在无需明确标签训练的情况下,即在没有针对特定疾病进行训练的情况下,仅通过输入提示词(如“存在胸腔积液”)就能检测疾病,展现了卓越的异常检测能力。在CT-RATE内部验证集中,CT-CLIP的零样本表现显著优于全监督基线模型(CT-Net),其平均AUROC提高了0.102,F1分数提高了0.050。 为了验证泛化能力,研究在两个外部数据集(RAD-ChestCT和UPMC,来自不同国家和设备)上进行了测试。结果显示,CT-CLIP在外部数据集上依然保持领先,AUROC分别提升了0.085和0.087。此外,研究还提出了VocabFine(开放词汇微调)和ClassFine(线性探测微调)策略,进一步提升了特定任务的检测精度,同时保留了模型的开放词汇推理能力。 图 3 | 微调CT-CLIP及其验证策略。 a,CT-CLIP的线性探测微调方法(ClassFine)示意图,即在视觉编码器中加入一个线性层。b,ClassFine支持多异常分类,但仅限于微调期间预定义的类别。c,CT-CLIP的开放词汇微调方法(VocabFine)示意图。d,VocabFine允许在微调后仍进行开放词汇异常分类,尽管其受限于微调期间提供的提示词。e,验证策略:模型在来自土耳其的CT-RATE数据集上训练,随后在内部验证集及两个来自美国的外部数据集上测试。f,比较:在三个不同队列中对CT-CLIP、两个微调模型及全监督方法进行了多异常检测的综合评估。 图 4 | CT-CLIP的详细评估。 a,在内部及两个外部验证集上使用四个关键指标评估多异常分类性能。CT-CLIP在所有指标上均优于全监督基线。微调技术(VocabFine/ClassFine)进一步提升了性能,证明了编码器特征提取的鲁棒性。b,CT-CLIP零样本检测使用了不同的提示词(Prompts)。图中高亮显示了表现最佳的提示词,突出了提示词工程的重要性。c,通过使用CT-RATE不同比例的数据量训练CT-CLIP,探索性能随数据集规模的变化(数据量越大性能越好)。d,t-SNE投影图:展示了病例中异常数量的分布。e,t-SNE投影图:展示了患者年龄的分布。聚类结果显示,老年患者的CT体积和报告往往对应更多的异常数量,表明年龄与疾病患病率之间存在相关性。 2) 病例检索(Case Retrieval) 利用CT-CLIP统一的嵌入空间,模型支持“以图搜图”(Image-to-Image Retrieval)和“以文搜图”(Text-to-Image Retrieval)。评估显示,CT-CLIP能够根据余弦相似度准确检索出具有相似病理特征的历史病例,其性能显著优于随机基线。这为放射科医生寻找参考病例、辅助决策提供了强有力的工具。 图 5 | 使用CT-CLIP检索3D胸部CT体积。 a,利用CT-CLIP内部的视觉编码器进行“体积到体积(Volume-to-volume)”的检索。b,利用CT-CLIP内部的视觉和文本转换器进行“报告到体积(Report-to-volume)”的检索。c,在内部和外部验证集上对“体积到体积”检索性能的综合评估,彩色高亮显示了优于随机分数的改进幅度。即使是微调后的模型,其检索准确率也保持相似。d,由于外部验证集缺乏配对的放射学报告,“报告到体积”检索的评估仅限于内部验证集。值得注意的是,针对分类任务微调CT-CLIP会降低其检索性能(尤其是VocabFine对文本转换器的影响)。
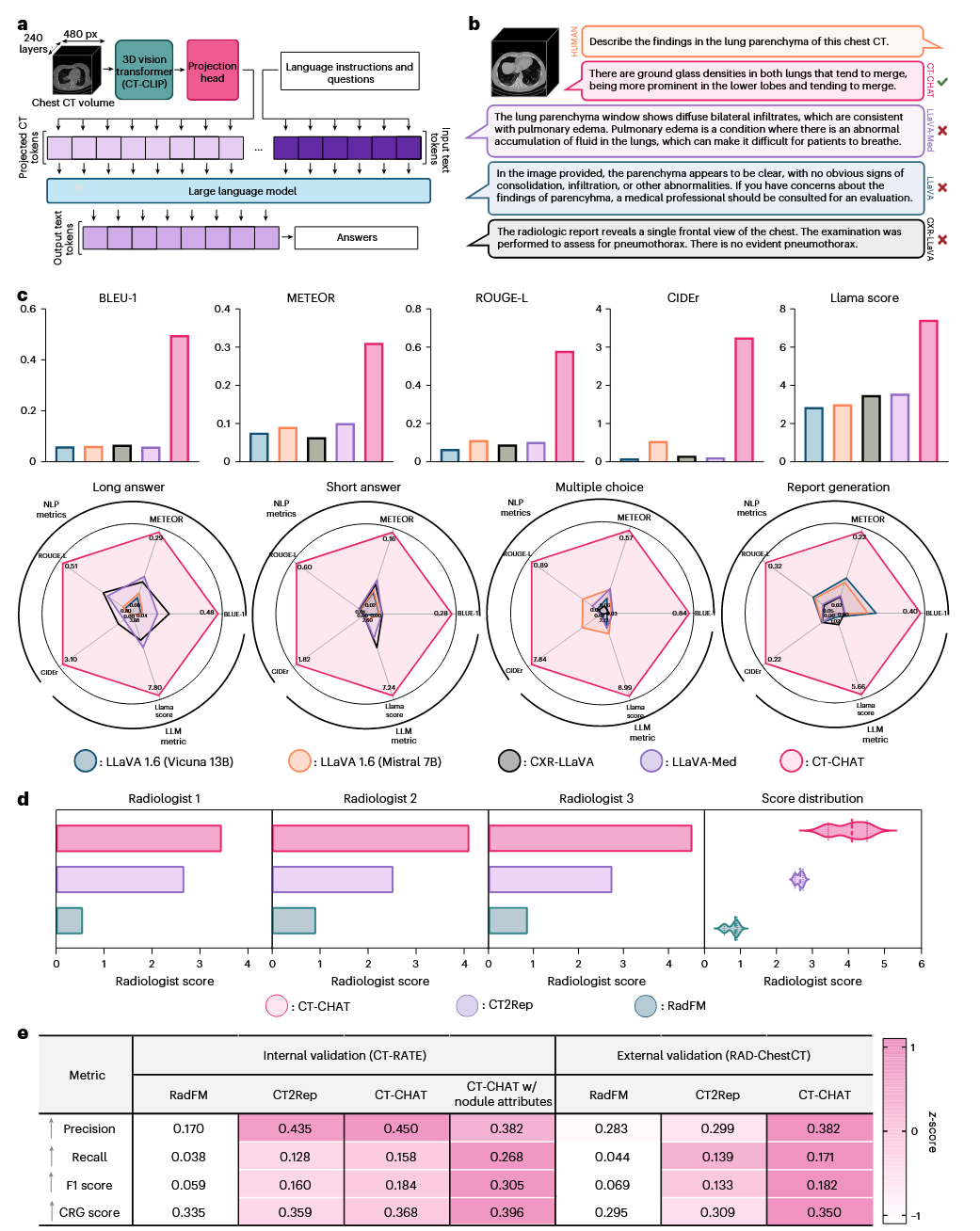
3) 交互式AI助手与报告生成(Multimodal AI Assistant) CT-CHAT在视觉问答(VQA)和报告生成任务中表现出色。与现有的2D多模态模型(如LLaVA-Med, CXR-LLaVA)及3D报告生成模型(RadFM,CT2Rep)相比,CT-CHAT在所有关键指标(BLEU, METEOR, ROUGE-L, CIDEr, Llama score)上均取得领先。 在包含三位资深放射科医生的专家评估中,医生对生成报告的临床准确性进行了0-10分的打分。结果显示,CT-CHAT的平均得分(3.44, 4.10, 4.52)显著高于RadFM(0.55-0.91)和CT2Rep(2.52-2.74)。特别是当结合了3D结节分割信息作为提示时,报告的生成质量进一步提升,展现了其作为临床辅助工具的巨大潜力。高质量3D模型的持续开发和集成对于临床可部署的AI系统至关重要。通过提供首创的资源和基准,特别是通过CT-RATE,工作朝着这一目标迈出了重要的一步,尽管常规临床使用仍然存在重大挑战。 图 6 | CT-CHAT的概览与详细评估。 a,CT-CHAT 的架构:专为 3D 胸部 CT 设计的视觉-语言 AI 助手。通过使用 CT-CLIP 视觉编码器编码的 CT token,在 SOTA 大语言模型(Llama 3.1)上微调 LoRA 权重进行训练。b,示例输出:展示了 CT-CHAT 相比于仅使用 DRR(数字重建放射影像)的 2D 模型,具有更优越的性能。c,在五个关键指标上评估了不同视觉-语言助手在问答任务上的性能,雷达图(Radar charts)提供了详细分解。d,报告生成性能:由三位委员会认证的放射科医生评估,小提琴图(Violin plot)确认了 CT-CHAT 的明显优势。e,使用临床效能指标(通过自动报告标注器计算)评估报告生成性能,以评估两个测试集上多项发现的临床正确性。
这项研究通过发布 CT-RATE 数据集、CT-CLIP 基础模型和 CT-CHAT 对话模型,填补了 3D 医学影像领域通用基础模型的空白。CT-CLIP 证明了利用现有放射学报告进行自监督学习,可以在不依赖人工标注的情况下实现超越监督学习的性能;而 CT-CHAT 则展示了将 3D 视觉特征与大语言模型结合后,在复杂临床问答和报告生成方面的强大能力。 尽管成果显著,研究团队也指出了当前的局限性:首先,单一机构数据集固有的偏见可能会影响模型的自我监督训练。尽管研究团队整理了大量且多样化的卷报告对,但数据源自单一地理和临床环境,这可能会限制模型对其他人群的普遍适用性。其次,CT-CLIP 取决于报告中使用的具体术语以及零样本检测期间提示的选择。放射学报告中疾病描述方式的差异可能会影响检测的准确性。第三,由于缺乏经过预训练的 3D 医学多模态 AI 助手进行基准测试,CT-CHAT 的评估面临局限性。最后,当前的模型仅限于胸部 CT 体积。为了扩大其临床适用性,未来的工作应侧重于扩展 CT-RATE、CT-CLIP 和 CT-CHAT,以包括其他 3D 成像模式,例如 MRI 和 PET 扫描以及其他解剖区域。扩展到不同的模式和身体部位将增强模型在更广泛的医学成像任务和临床场景中的使用。 总之,CT-CLIP和CT-CHAT的发展标志着3D医学成像向前迈出了一大步。这些模型由开源 3D 数据集 CT-RATE 与放射学报告相结合,为该领域的多模式 AI 设定了基准。它们的开放可用性为未来的研究并最终为临床可部署系统的开发奠定了坚实的基础。
Hamamci, I.E., Er, S., Wang, C. et al. Generalist foundation models from a multimodal dataset for 3D computed tomography. Nat. Biomed. Eng (2026). https://doi.org/10.1038/s41551-025-01599-y
END 撰文 | 程虞茜、姜泽坤 编辑 | 余帆 审核 | 医工学人理事会 扫码加入医工学人,进入综合及细分领域群聊,参与线上线下交流活动
推荐阅读
Microsystems & Nanoengineering | 告别扎针!新型“光学智能手表”结合等离激元纳米阵列,实现无创汗液血糖监测 点击关注医工学人
本篇文章来源于微信公众号: 医工学人
