






星标“医工学人”,第一时间获取医工交叉领域新闻动态~

当人们还在讨论GPT-4能否通过医学考试时,来自美国国立卫生研究院、耶鲁大学和弗罗里达州立大学等机构的顶尖学者们,已经构建了一个更进一步的AI系统——AgentMD,于2025年10月23日发表在《Nature Communications》上。它不只是一个“万事通”的聊天机器人,而是一个真正的“AI代理”(AI Agent)。它能像资深医生一样,自主学习并“制造”工具,然后再使用这些工具来解决复杂的临床问题,展现了惊人的能力:它通过阅读海量的PubMed文献,自动构建了一个包含2164个可执行的临床计算器(RiskCalcs)的庞大工具库。
更令人瞩目的是,当面对复杂的风险预测任务时,配备了这些工具的AgentMD准确率高达87.7%。而在同一任务上,GPT-4的准确率仅为40.9%。
在现代临床实践中,医生们依赖数百种临床评分计算器来进行风险评估——例如,用“HEART评分”评估胸痛患者的心脏事件风险。这些工具至关重要,但使用起来却困难重重。
“临床医生面临着巨大的认知负荷,”该研究指出。他们必须准确知道何时该用哪个工具,这在紧张的临床工作中几乎不可能。更糟糕的是,这些工具与电子病历(EHR)系统严重脱节,医生必须手动从病历中查找数据,再输入临床评分计算器。这个过程不仅效率低下,而且极易出错。通用的大型语言模型(LLM)也无法解决这个“最后一公里”的难题。研究显示,即便是GPT-4,在被要求进行精确的医学计算时,也表现不佳。“医疗需要的是精确,而不是‘大概如此’。” AgentMD的研究者们显然意识到了这一点。
在临床工具学习领域,确实存在其他尝试。例如,论文中提到,OpenMedCalc依赖手动策划,这限制了其规模和可扩展性。而Almanac系统采用检索增强生成(RAG),它检索的是工具的“文本描述”,在进行需要精确计算的算术任务时可能不够准确。对比起来,AgentMD展现了显著的差异和优势。AgentMD则属于更广泛的“工具增强型LLM”或“AI代理”趋势,类似于GeneGPT或其他利用外部工具(如搜索引擎)的代理,但AgentMD的独特之处在于它不仅“使用”工具,还大规模地“创建”了这些工具,并将其实现为可复用的“程序”,从而保证了在医疗这一高风险领域所需的计算精度和可泛化性。
AgentMD的设计理念极具创新性,它拥有一个“双重角色”的架构。

图1:AgentMD工具整理与使用概览。a.由AgentMD基于一篇关于CURB-65风险评分的PubMed文章(PMID: 12728155)的标题和摘要,在RiskCalc工具包中整理出的临床评分计算器示例。b.AgentMD作为工具使用者的工作方法,包括工具选择、工具计算和结果总结。
首先,它是“工具构建者”(Tool Builder)。
研究团队没有采用传统的人工方式去收集工具,而是让AgentMD自主“学习”。AgentMD执行了一个三步走的自动化流程:
1.筛选:它首先“阅读”了PubMed上近34万篇医学摘要,利用GPT-3.5筛选出3.3万篇可能描述了风险计算器的文章。
2.起草: 接着,GPT-4介入,从这些文章中“起草”了2.4万个结构化的计算器工具。
3.验证: 最后,AgentMD利用GPT-4进行“自我核查”,通过6项严格标准(例如,计算逻辑是否与原文一致?),最终生成了2164个高质量、可执行的Python函数工具。
这个名为RiskCalcs的工具库,其质量和覆盖范围都令人印象深刻。它不仅通过了超90%的单元测试,更重要的是,它填补了巨大的空白——研究者随机抽样发现,高达96%的工具是目前主流医学计算网站(如MDCalc)所没有的。
其次,它是“工具使用者”(Tool User)。
拥有了强大的工具库后,AgentMD开始扮演“操作员”的角色。当给定一份真实的患者病历时,AgentMD会:
1.选择工具:它首先分析病历,然后从2164个工具中自主选择最相关的计算器(例如,为肺炎患者选择CURB-65评分)。
2.执行计算: 它不是用语言模型去“猜”结果,而是调用Python解释器来执行该工具的代码。这确保了计算过程的绝对精确。
3.总结报告:最后,它将计算结果(如“CURB-65得分1,死亡风险3.2%”) 汇总,提供给医生。
AgentMD 的表现并非纸上谈兵。研究团队在多个维度上对其进行了严酷的测试。
在专门构建的RiskQA基准测试(一个包含350道USMLE风格多项选择题的数据集)上,AgentMD (GPT-4) 取得了87.7%的准确率。相比之下,没有工具辅助、仅靠“思考”的GPT-4 (CoT) 准确率仅为40.9%。这一对比有力地证明了“工具赋能”的巨大价值。
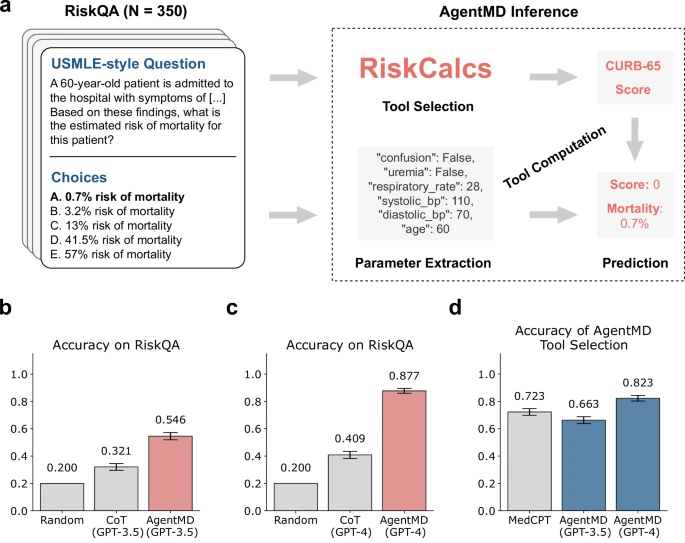
图2:AgentMD在RiskQA上的评估。a,RiskQA中的一个问题示例以及AgentMD如何回答它。b,基于GPT-3.5的AgentMD与思维链提示在RiskQA上的性能比较。c,基于GPT-4的AgentMD与思维链提示在RiskQA上的性能比较。d,MedCPT和AgentMD在工具选择上的准确率。(b-d)中的准确率(中心线)定义为所有问题(N=350)中正确回答问题的比例。
在更严苛的真实世界测试中,AgentMD被用于分析698份来自耶鲁大学急诊科的真实患者笔记。结果显示,在80.6%的案例中,AgentMD选择的工具被医生评估为“适用”;在超过80%的适用案例中,其计算过程被评为“正确”或“部分正确”。
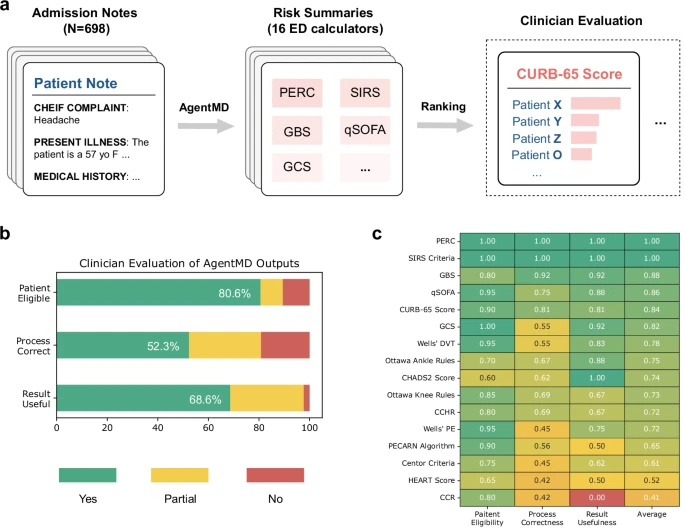
图3:在急诊科医生病历上进行的个体层面评估结果。a,AgentMD使用一个包含16个常用计算器的工具包,应用于耶鲁医学院的急诊科医生病历。对于每个计算器,根据总体风险对患者进行排序,并选择排名前5位的患者进行评估。b,在所有患者-计算器配对上,临床医生注释结果的分布情况。c,按计算器分组的评估结果(跨患者和注释者平均),并按平均分数进行排序。
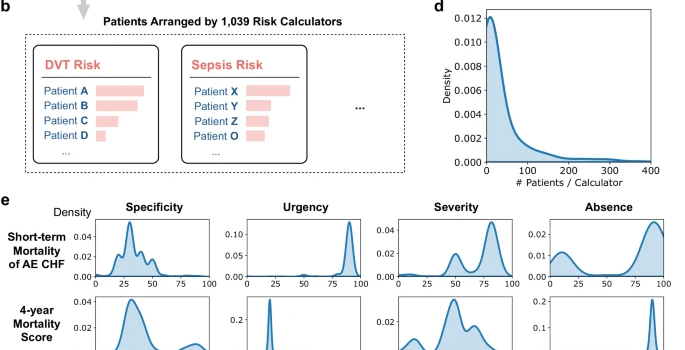
在对MIMIC-III数据库中9822名患者的大规模分析中,AgentMD成功提供了群体级别的风险洞察。研究团队甚至发现,AgentMD使用的113种计算器,在预测院内死亡率方面,其表现优于原生的GPT-4。
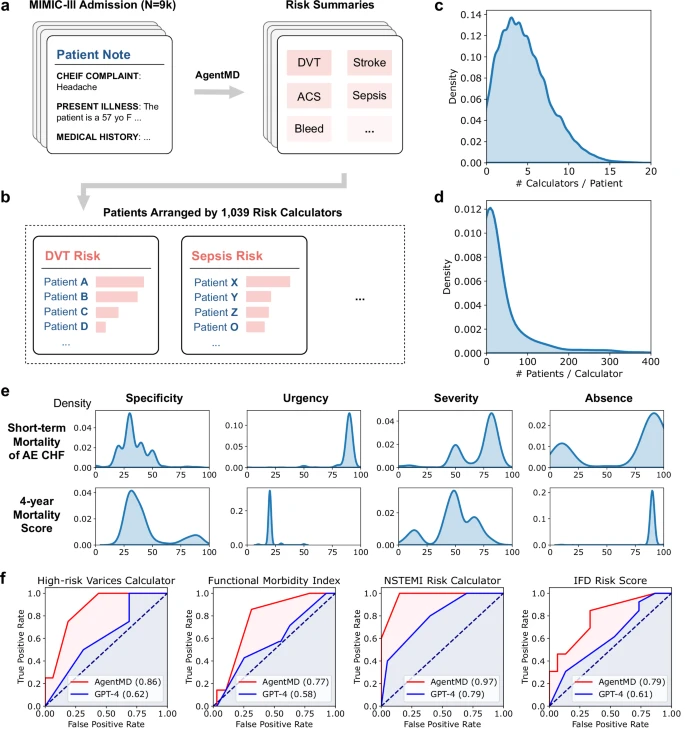
图4:在MIMIC队列上应用AgentMD。a,AgentMD被应用于MIMIC数据库中的9822份入院病历。b,AgentMD的计算结果按风险计算器进行汇总,并在每个工具内对患者进行排序。c,每位患者被选用的计算器数量分布。d,每个被使用的计算器所适用的患者数量分布。e,来自两个计算器的计算结果分布。f,临床计算器的样本ROC曲线,显示AgentMD在预测院内死亡率方面优于GPT-4。
总而言之,AgentMD是一项极具开创性的研究,它为AI Agent如何深入赋能高风险、高专业的医疗领域提供了一个卓越的范例和清晰的蓝图,同时也为其他行业(如金融、法律、工程)指明了AI发展的新路径。
该研究的核心贡献不仅是构建了一个性能优越的AI系统,更重要的是,它创建了一套可扩展的“基础设施”——即自动从文献中生成并验证可执行工具(RiskCalcs)的方法论。AgentMD (GPT-4) 相较于GPT-4 (CoT) 在RiskQA上87.7% vs 40.9%的巨大性能差异,雄辩地证明了一个核心观点:对于专业的、需要精确计算的领域(如医疗),通才的LLM是不够的,必须为它们配备精确、可验证的专用工具。
当然,正如作者在讨论中坦承,研究仍有局限性,例如仅使用摘要而非全文,对昂贵闭源模型(GPT-4)的依赖,以及主要集中于文本模态。同时,作者也强调,在真正部署于需要高度精准临床工作流之前,还需要更全面的评估。
尽管如此,AgentMD作为连接海量医学知识(文献)与临床实践(患者病历)的桥梁,其展现的潜力是巨大的。它预示着一个未来——AI不仅是医生的“知识库”,更是能够自主使用专业工具、执行复杂计算的“得力助手”。
[1]Jin, Q., Wang, Z., Yang, Y. et al. AgentMD: Empowering language agents for risk prediction with large-scale clinical tool learning. Nat Commun 16, 9377 (2025). https://doi.org/10.1038/s41467-025-64430-x END 编辑 | 郝娅婷 排版 | 张艳青 审核 | 医工学人理事会
扫码加入医工学人,进入综合及细分领域群聊,
参与线上线下交流活动

推荐阅读
点击关注医工学人 最新直播

本篇文章来源于微信公众号: 医工学人
